任务调度管理
任务调度管理的在日常开发中很常见,比如启动时任务管理就是其中一种。在大型的项目中,通常存在很多任务的调度,这些任务之间往往存在很多依赖关系。如果单纯依赖手动管理,很容易造成后期维护成本过高的问题,这种问题主要表现在:
-
需要人工维护依赖关系
-
任务之间调度不明确
-
多依赖条件下任务混乱,后期任务新增或者删除困难
因此在大型的项目中,通常都会有自己的任务调度管理框架,今天我们将来实现在鸿蒙next系统上的任务调度管理框架Factotum。
通过本篇你将会了解到拓扑排序实现,以及如何在鸿蒙系统中使用Hvigor插件编译时构造拓扑排序解析,在运行时通过装饰器进行解析结果的调度。
本篇设计的代码均开源,大家可以从Factotum中查看
任务调度核心算法
任务,我们可以抽象为一个个节点,任务之间的依赖关系我们就可以抽象为两个节点之间的边。有向无环图(Directed Acyclic Graph,简称DAG)是一种经常处于任务调度使用的数据结构,它指的是一个无回路的有向图。这意味着在这个图中,不存在从一个顶点出发,沿着边经过若干个顶点后又回到该顶点的路径。
结点之间相互依赖,我们可以称为循环依赖问题,也叫成环问题,如下图

任务管理框架需要识别当前的任务中是否成环,成环的话就要及时终止当前循环任务并给出依赖,如果不存在成环的情况,那么我们其实是可以把整个有向无环图铺平,即拓扑排序(拓扑排序(Topological Sorting)是一种针对有向无环图的特殊排序方法。它将图中的所有顶点排成一个线性序列) 。利用拓扑排序我们能让有依赖关系的任务按照线性执行且不影响任务之间的依赖关系。
Factotum中,一个任务是实现ITask接口的一个类对象
export interface ITask{
onLaunch()
}
也就是说,我们接受框架使用者提供的各个ITask,并解析其依赖关系生成一个拓扑排序后的数组。在任务调度执行时我们按照拓扑排序的结果执行是整个框架的设计目标。
那么我们怎么实现拓扑排序呢?这里给出一个基于BFS(广度优先遍历算法的实现)
基于 BFS 的拓扑排序算法的步骤如下:
- 计算图中每个节点的入度:遍历所有边,统计每个节点的入度(即指向该节点的边的数量)。
- 创建一个队列,将所有入度为 0 的节点加入队列。这些节点没有前驱节点,可以立即处理。
- 进入循环:当队列非空时进行如下操作:
a. 从队列中取出一个节点,将其添加到拓扑排序的结果列表中。
b. 遍历以此节点为开头的所有边,将边的终点的入度减 1。如果边的终点入度变为 0,则将其加入队列,表示可以处理此节点。
c. 删除此节点及其边。
- 如果结果列表中的节点数量与图中节点数量相同,则说明所有节点都被处理,拓扑排序成功。如果不相同,说明图中存在环,拓扑排序失败。
对应的TS代码如下:
detectCycleNodes(): string[] {
let indegree = new Map<string, number>()
let queue:string[] = []
let cycleNodes:string[]=[]
this.taskGraph.forEach((value: string[]) => {
value.forEach((node)=>{
indegree.set(node,(indegree.get(node) ?? 0) + 1)
})
})
this.taskGraph.forEach((value: string[], key: string) => {
let currentNode = indegree.get(key) ?? 0
if (currentNode == 0) {
queue.push(key)
}
})
let count = 0
let result: string[] = []
while (queue.length > 0) {
let node = queue.pop()
result.push(node)
count++
this.taskGraph.get(node)?.forEach((it: string) => {
indegree.set(it,indegree.get(it) - 1)
if (indegree.get(it) == 0) {
queue.push(it)
}
})
}
if (count != this.allTaskSet.size) {
indegree.forEach((value: number, key: string) => {
if (value > 0) {
cycleNodes.push(key)
}
})
throw new Error(`Found cycle dependencies: ${cycleNodes.join(", ")}`)
}
return result
}
编译时有向无环图构建
为什么要选择在编译时构建有向无环图呢,主要目的有两个,其一是有向无环图的构建本身也会有一定的时间复杂度,对于启动时任务这种常见来说,当然是构建时间越短越好,编译时的任务能够在性能上取得最优。其二是对于任务循环依赖的场景下(成环),在复杂任务开发中,开发人员可能因为任务依赖不明确从而编写导致死循环的场景(Task1依赖Task2,Task2又依赖Task1),这种情况下如果能够在编译时就即使中断任务的话,就能够极大程度避免隐藏的bug带到线上,相反如果在运行时的话,那么就必须得等到APP启动后才能知道。
实现编译时Hvigor插件
在鸿蒙应用中,我们可以通过自定义编写Hvigor插件,从而实现能够在默认的任务流程中添加属于自己的逻辑
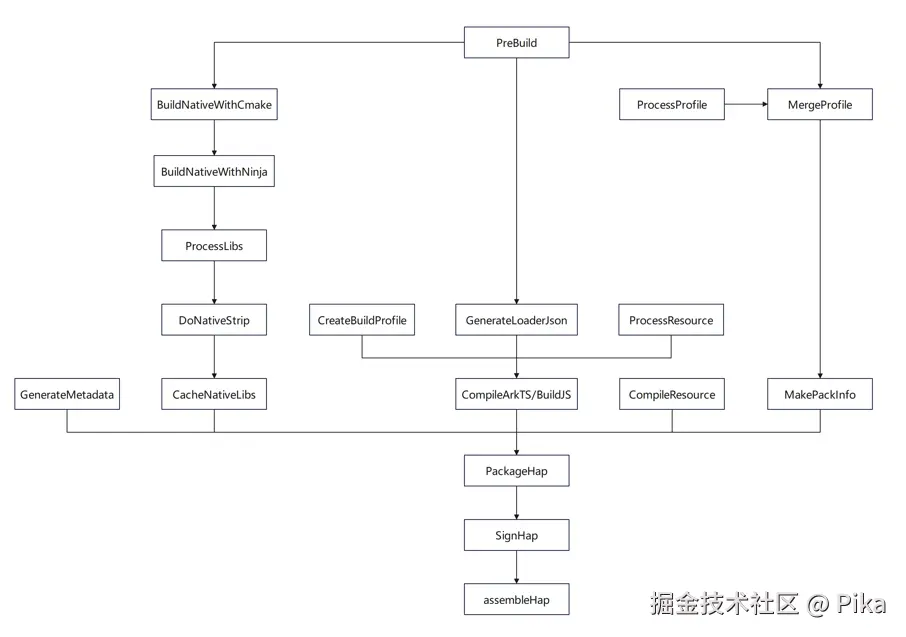
整个HAP构建系统中,有着很多不同的构建任务,当前构建任务会像下一个构建任务传递自己的构建参数,我们通常所需要的构建产物就是源代码,因为很多时候我们可以通过解析源代码的AST(抽象语法树)帮助我们在编译时生成必要的东西。实现一个Hvigor插件,我们需要在hvigorfile.ts文件中只需定义一个pluginId(任务Id)和name(任务名称)

本例子中,我们定义一个自定义的factotumHapPlugin插件
export default {
system: hapTasks,
plugins:[factotumHapPlugin()]
}
自定义插件需要继承于HvigorPlugin类
export function factotumHapPlugin(): HvigorPlugin {
return {
pluginId: HAP_PLUGIN_ID,
apply(node: HvigorNode) {
FactotumTask(node, OhosPluginId.OHOS_HAP_PLUGIN)
}
}
}
在整个构建阶段,我们可以通过HvigorNode 对象获取必要的上下文信息(OhosHapContext | OhosHarContext | OhosHspContext)根据你的hvigor插件执行的环境不同类型也有不同,同时我们也可以通过HvigorNode注册一个自己的任务,通过registerTask方法即可。因为我们需要根据装饰器来获取任务依赖的信息,比如名称以及下一个任务的依赖,因此我们需要的是可提供我们直接进行语法树分析的源码而不是abc字节码。为了满足这个需求,我们可以在PreBuild任务执行后插入自定义任务即可,dependencies为前置依赖任务,postDependencies为后置依赖任务,我们可以根据上文任务构建图选择合适的时机
hvigor.nodesEvaluated(async () => {
const context = node.getContext(pluginId) as ContextLike
if (!context) {
throw new Error('errorMsg: context is null 请检查插件的hvigorfile配置')
}
context.targets((target: Target) => {
const targetName = target.getTargetName()
node.registerTask({
name: `${targetName}@FactotumPluginTask`,
run: () => {
let plugin = new FactotumPlugin(new FactotumConfig(node.getNodeName(), node.getNodePath()))
plugin.analyzeAnnotation('src/main/ets/_generated')
let taskName = 'Package' + pluginId.split('.')[2].charAt(0).toUpperCase() + pluginId.split('.')[2].slice(1)
node.getTaskByName(`${targetName}@${taskName}`)?.afterRun(() => {
})
},
dependencies: [`${targetName}@PreBuild`],
postDependencies: [`${targetName}@MergeProfile`]
})
})
})
解析抽象语法树
进行抽象语法树的前提是,获取到对应的源码。在开发插件中,我们通常需要获取源码的路径,比如本例子中需要解析的文件在src/main/ets 中,因为我们需要获取到对应目录下的ets文件进行解析,那么如何获取到当前插件对应的路径呢?我们可以通过HvigorNode对象的getNodePath()获取当前的路径,获取路径后我们自然就可以通过相对路径获取到对应其他路径的文件了,比如本例子中目标产物的地址getNodePath()+/src/main/ets 中的ets或者ts文件
收集好目标文件后,我们就可以进行文件级别的解析了
this.scanFiles.forEach(filePath => {
if (filePath.endsWith('.ets') || (filePath.endsWith('.ts'))) {
const analyzer = new Analyzer(filePath)
let result = analyzer.start()
if (result.length > 0) {
finalResult = finalResult.concat(result)
}
}
})
我们来看一下如何通过源码进行抽象语法树解析,通过TypeScript 提供的createSourceFile,我们即可获得一个编译中间产物
const sourceCode = fs.readFileSync(this.sourcePath, 'utf-8')
const sourceFile = ts.createSourceFile(
this.sourcePath,
sourceCode,
ts.ScriptTarget.ES2021,
false
)
比如我们有一个测试文件test1.ets,他的源码是
@Launcher({
launchName:"Test1"
})
export class Test1 implements ITask{
onLaunch(): void {
hilog.error(0, "hello", "Test1 onLaunch")
}
}
通过createSourceFile,我们在通过forEachChild遍历,可以获取到为ts.Node的对象,这个就是抽象语法树的子节点
ts.forEachChild(sourceFile, node => {
this.resolveNode(node)
})
forEachChild的实现在
export function forEachChild(node: Node, cbNode: (node: Node) => T, cbNodeArray?: (nodes: Node[]) => T): T {
if (!node) {
return;
}
switch (node.kind) {
case SyntaxKind.BinaryExpression:
return visitNode(cbNode, (<BinaryExpression>node).left) ||
visitNode(cbNode, (<BinaryExpression>node).operatorToken) ||
visitNode(cbNode, (<BinaryExpression>node).right);
case SyntaxKind.IfStatement:
return visitNode(cbNode, (<IfStatement>node).expression) ||
visitNode(cbNode, (<IfStatement>node).thenStatement) ||
visitNode(cbNode, (<IfStatement>node).elseStatement);
关于抽象语法树的知识,可以前往TypeScript项目中查看,因为整个TypeScript是开源的,我们这里不多展开,简单来说就是源码会经过编译生成一系列更近底层的表达式,这些表达式会有独立的一个个节点组成,我们可以通过TypeScript AST Viewer查看对应的产物

因为我们的目标是解析@Launcher 装饰器里面的内容,因此按照树遍历的方式,一步步解析到最终的产物(叶子结点)即可
private resolveNode(node: ts.Node) {
if (ts.isClassDeclaration(node)) {
this.resolveClass(node)
} else if (ts.isDecorator(node)) {
this.resolveDecorator(node)
}
}
private resolveClass(node: ts.ClassDeclaration) {
node.modifiers?.forEach(modifier => {
this.resolveNode(modifier)
})
}
@Launcher 中的Test1 是我们的希望获取到的最终结果
@Launcher({
launchName:"Test1"
})
Test1 最终是一个StringLiteral 结点,通过.text即可获取到最终的“Test1”
private parseAnnotation(args: ts.NodeArray至此,我们得到了最终的产物,即当前任务的名称以及依赖的其他任务,接下来我们就可以通过上文说到的拓扑排序构造有向无环图了。
可能有读者会问,为什么我们需要费这么大心思去解析抽象语法树而不是源码呢?这是因为只有抽象语法树的产物,即Node才是独立的参数,源码还是属于面向开发者的表达式,同样的一串代码比如:
@Launcher({
launchName:"Test1"
})
@Launcher({launchName:"Test1"})
@Launcher({launchName:"Test1"
})
其实在源码中有无数种表示,因为这取决于为了方便编写代码,比如格式更加好看等方便程序开发者的操作,编程语言允许在这其中会引入很多无用的符号比如空格等,但是这些最终的产物都是同一颗抽象语法树。因此解析抽象语法树才是最优解才能确保我们最终产物的正确。
生成拓扑排序产物
我们通过解析抽象语法树得到了一系列任务以及其依赖的任务,进行拓扑排序后我们就可以得到一个数组,这个数组就满足了正常的任务启动所需要的依赖关系。但是我们怎么把这个产物在后面启动任务时利用起来呢?这就需要我们保存此次编译的结果了。
在Hvigor插件中,提供了在编译时文件生成的能力,我们可以通过fs.writeFileSync 方法生成一个文件,通常为了文件的生成,我们需要一些脚手架帮忙。我们目标是通过解析拓扑排序的结果,生成一个方法,方法返回对应的内容,为了完成这项任务,我们可以通过handlebars 这个工具帮忙,因为我们需要一些模板更加方便以后扩展,当然你手写其实也是没问题的,但是维护起来会比较麻烦,比如kotlin代码生成中我们可以利用KotlinPoet。Handlebars更加方便我们生成这些文件
Handlebars 是一种简单的 模板语言。它使用模板和输入对象来生成 HTML 或其他文本格式。Handlebars 模板看起来像常规的文本,但是它带有嵌入式的 Handlebars 表达式 。
<p>{{firstname}} {{lastname}}p>
Handlebars 表达式是一个 {{}}。执行模板时,这些表达式会被输入对象中的值所替换,本例子中,我们可以通过以下方式定义我们的模板
import { FactotumLauncher, ITask } from 'factotum';
export function getGraph():string[] {
return [
{{#each graphs}}
"{{this}}",
{{/each}}
]
}
export function LauncherManager(info: ITask[]) {
return (target: Function) => {
FactotumLauncher.getInstance().setGraphInner(getGraph())
FactotumLauncher.getInstance().addTasks(info);
};
}
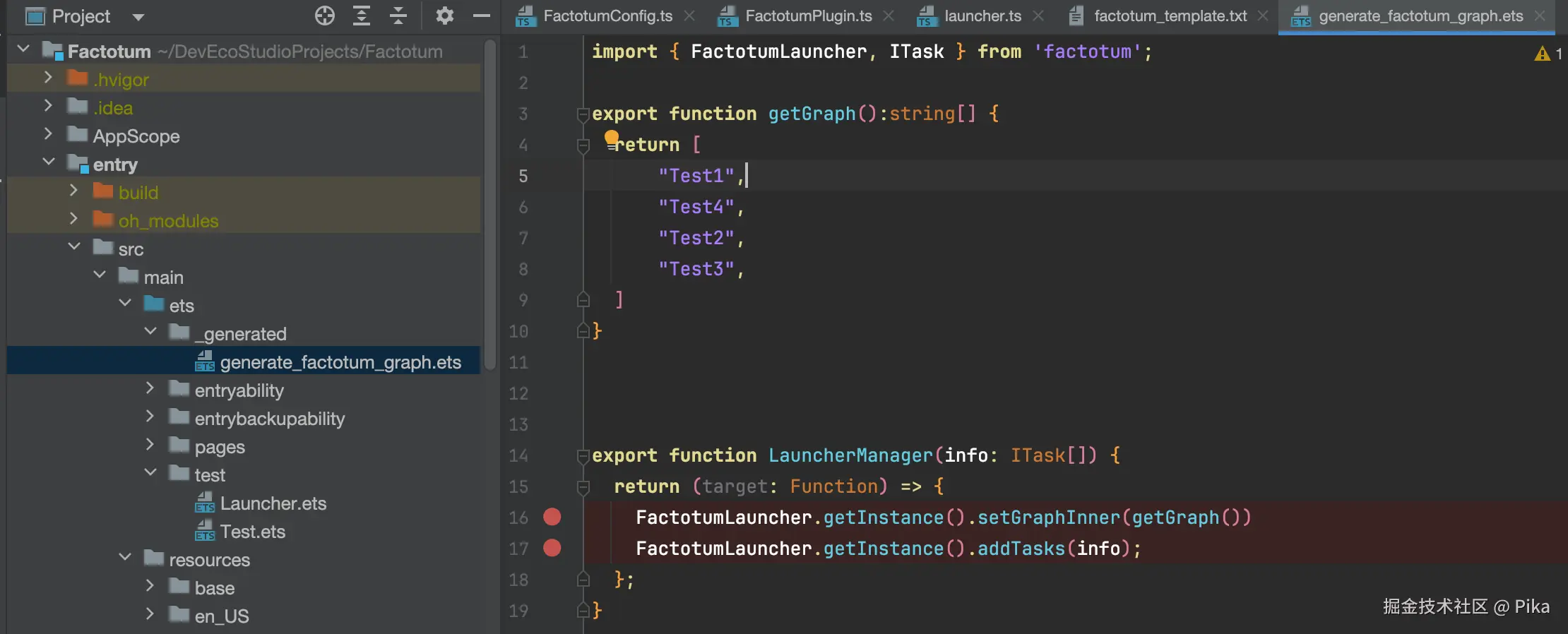
getGraph 方法中接受graphs参数,即通过拓扑排序后的数组,把生成好的产物写入一个文件即可
generateGraph(target: string[],generatePath:string) {
const builderPath = path.resolve(__dirname, 'factotum_template.txt')
Logger.info(`builderPath is ${builderPath}`)
const tpl = fs.readFileSync(builderPath, { encoding: 'utf-8' })
const template = Handlebars.compile(tpl)
const content = { graphs: target }
const output = template(content)
Logger.info(`output is ${output}`)
const modDir = this.config.modulePath
const routerBuilderDir = `${modDir}/${generatePath}`
if (!fs.existsSync(routerBuilderDir)) {
fs.mkdirSync(routerBuilderDir)
}
fs.writeFileSync(`${routerBuilderDir}/generate_factotum_graph.ets`, output, {
encoding: 'utf-8'
})
Logger.info(`routerBuilderDir ${routerBuilderDir}`)
}
对应的参数示例如下
运行时启动任务框架
在编译时我们只是对一个任务名称进行的排序,那么怎么把任务名称与一个个的具体的任务对应起来呢?这里我们就可以利用装饰器运行时的特点,在运行时对具体的任务进行映射重建过程。Factotum通过在运行时针对任务的prototype对应进行了隐式的属性生成,从而实现对launchName与具体的ITask进行绑定
export interface LaunchInfo {
launchName: string,
dependencies?: string[]
}
export const LAUNCH_TAG = "factotum_tag"
export function Launcher(info: LaunchInfo) {
return function(target: any) {
target.prototype[LAUNCH_TAG] = info.launchName
};
}
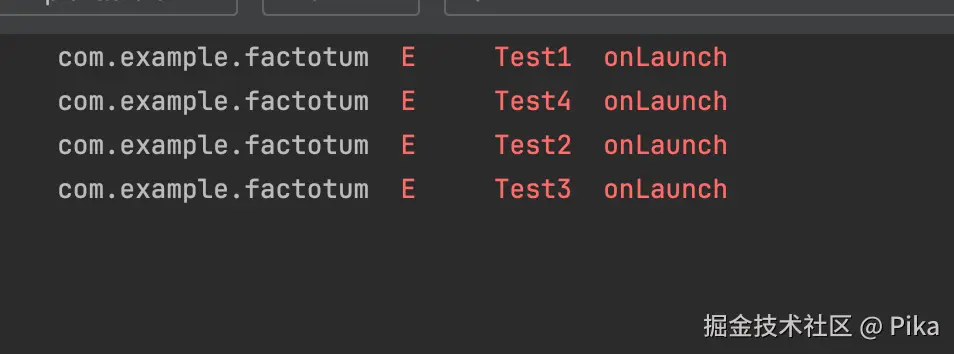
当然了,得到编译后的产物还不够,因为我们需要一个时机去启动整个任务框架,因此我这里设计了另外一个装饰器,当装饰器加载时即可执行对应的逻辑。因为我们需要一个时机去加载,Factotum提供了launchAll 方法,执行编译时得到的拓扑排序结果。
在这个设计期间,我们遇到了另外一个难题,那就是编译的产物其实只会存在使用者的module中,我们无法直接从底层module依赖上层module的产物。Factotum的做法是通过在编译时生成一个上层装饰器LauncherManager 从而允许上层使用者直接调用编译时生成拓扑排序结果
@LauncherManager([new Test1(),new Test2(),new Test3(),new Test4()])
export class Launcher{
launchAll(){
FactotumLauncher.getInstance().launchAll()
}
}
最终使用者无需关注任务的启动顺序,只需要按照需求把任务放入即可,任务启动框架会自动完成依赖顺序调度并输出对应的结果
总结
通过了解Factotum整体设计思路,我们了解到了一个最基本的任务调度框架所需要的能力,本篇涉及的源码均在Github中开源。我们通过学习Hvigor插件以及TypeScipt AST,能够让我们在编译时实现更加复杂的任务,相信通过本文读者能够掌握HarmonyOS中进阶开发的能力。
1、本站所有资源均从互联网上收集整理而来,仅供学习交流之用,因此不包含技术服务请大家谅解!
2、本站不提供任何实质性的付费和支付资源,所有需要积分下载的资源均为网站运营赞助费用或者线下劳务费用!
3、本站所有资源仅用于学习及研究使用,您必须在下载后的24小时内删除所下载资源,切勿用于商业用途,否则由此引发的法律纠纷及连带责任本站和发布者概不承担!
4、本站站内提供的所有可下载资源,本站保证未做任何负面改动(不包含修复bug和完善功能等正面优化或二次开发),但本站不保证资源的准确性、安全性和完整性,用户下载后自行斟酌,我们以交流学习为目的,并不是所有的源码都100%无错或无bug!如有链接无法下载、失效或广告,请联系客服处理!
5、本站资源除标明原创外均来自网络整理,版权归原作者或本站特约原创作者所有,如侵犯到您的合法权益,请立即告知本站,本站将及时予与删除并致以最深的歉意!
6、如果您也有好的资源或教程,您可以投稿发布,成功分享后有站币奖励和额外收入!
7、如果您喜欢该资源,请支持官方正版资源,以得到更好的正版服务!
8、请您认真阅读上述内容,注册本站用户或下载本站资源即您同意上述内容!
原文链接:https://www.dandroid.cn/archives/22101,转载请注明出处。

评论0