概述
管道流是用来在多个线程之间进行信息传递的Java流。
管道流分为字节流管道流和字符管道流。
字节管道流:PipedOutputStream 和 PipedInputStream。
字符管道流:PipedWriter 和 PipedReader。
PipedOutputStream、PipedWriter 是写入者/生产者/发送者;
PipedInputStream、PipedReader 是读取者/消费者/接收者。
字节管道流
这里我们只分析字节管道流,字符管道流原理跟字节管道流一样,只不过底层一个是 byte 数组存储 一个是 char 数组存储的。
java的管道输入与输出实际上使用的是一个循环缓冲数来实现的。输入流PipedInputStream从这个循环缓冲数组中读数据,输出流PipedOutputStream往这个循环缓冲数组中写入数据。当这个缓冲数组已满的时候,输出流PipedOutputStream所在的线程将阻塞;当这个缓冲数组为空的时候,输入流PipedInputStream所在的线程将阻塞。
注意事项
在使用管道流之前,需要注意以下要点:
- 管道流仅用于多个线程之间传递信息,若用在同一个线程中可能会造成死锁;
- 管道流的输入输出是成对的,一个输出流只能对应一个输入流,使用构造函数或者connect函数进行连接;
- 一对管道流包含一个缓冲区,其默认值为1024个字节,若要改变缓冲区大小,可以使用带有参数的构造函数;
- 管道的读写操作是互相阻塞的,当缓冲区为空时,读操作阻塞;当缓冲区满时,写操作阻塞;
- 管道依附于线程,因此若线程结束,则虽然管道流对象还在,仍然会报错“read dead end”;
- 管道流的读取方法与普通流不同,只有输出流正确close时,输出流才能读到-1值。
示例
public class PipedStreamDemo {
public static void main(String[] args) {
//创建一个线程池
ExecutorService executorService = Executors.newCachedThreadPool();
try {
//创建输入和输出管道流
PipedOutputStream pos = new PipedOutputStream();
PipedInputStream pis = new PipedInputStream(pos);
//创建发送线程和接收线程
Sender sender = new Sender(pos);
Reciever reciever = new Reciever(pis);
//提交给线程池运行发送线程和接收线程
executorService.execute(sender);
executorService.execute(reciever);
} catch (IOException e) {
e.printStackTrace();
}
//通知线程池,不再接受新的任务,并执行完成当前正在运行的线程后关闭线程池。
executorService.shutdown();
try {
//shutdown 后可能正在运行的线程很长时间都运行不完成,这里设置超过1小时,强制执行 Interruptor 结束线程。
executorService.awaitTermination(1, TimeUnit.HOURS);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
static class Sender extends Thread {
private PipedOutputStream pos;
public Sender(PipedOutputStream pos) {
super();
this.pos = pos;
}
@Override
public void run() {
try {
String s = "hello world, amazing java !";
System.out.println("Sender:" + s);
byte[] buf = s.getBytes();
pos.write(buf, 0, buf.length);
pos.close();
TimeUnit.SECONDS.sleep(5);
} catch (Exception e) {
e.printStackTrace();
}
}
}
static class Reciever extends Thread {
private PipedInputStream pis;
public Reciever(PipedInputStream pis) {
super();
this.pis = pis;
}
@Override
public void run() {
try {
ByteArrayOutputStream baos = new ByteArrayOutputStream();
byte[] buf = new byte[1024];
int len = 0;
while ((len = pis.read(buf)) != -1) {
baos.write(buf, 0, len);
}
byte[] result = baos.toByteArray();
String s = new String(result, 0, result.length);
System.out.println("Reciever:" + s);
} catch (IOException e) {
e.printStackTrace();
}
}
}
}输出结果:

源码分析
因为数据是从 PipedOutputStream 写入,然后通过 PipedInputStream 读取的,所以下面我们先来分析下 生产者 PipedOutputStream 的源码。
PipedOutputStream 源码分析
初始化
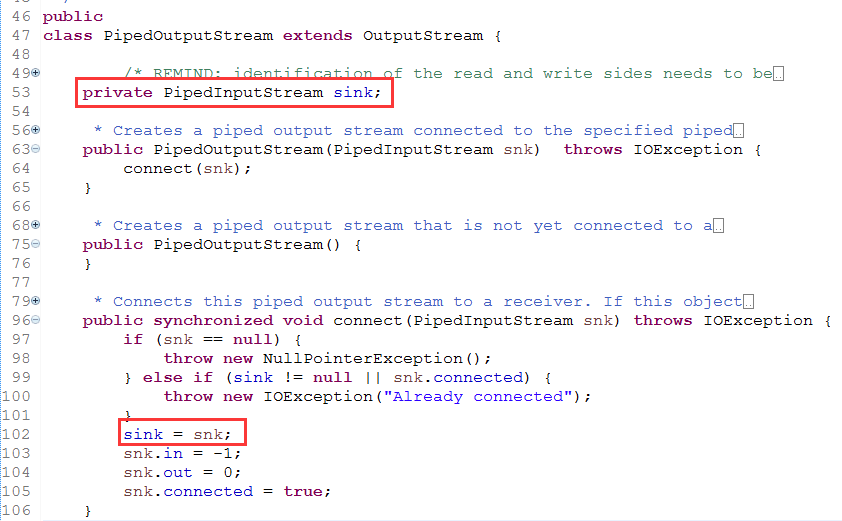
1、定义了一个 PipedInputStream 成员变量 sink。用来保存需要写入到的目标管道流中。
2、一个代参数的构造,一个无参的构造。
- 有参的构造调用 connect() 方法把两个管道流连接在一起,
- 无参的构造函数更灵活,不必在创建一个 PipedOutputStream 的对象时指定 PipedInputStream 对象,可以在后面代码,自己调用 connect() 自己指定。使用方式如下:

write 方法
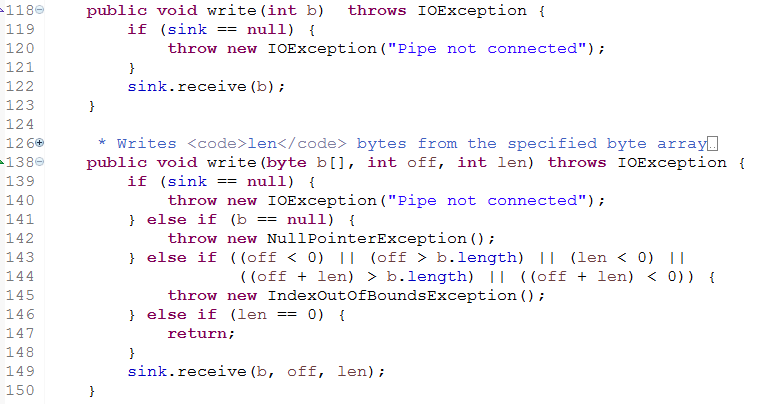
write 方法就是调用 PipedInputStream的 receive 的方法,把要写入的数据写入进去。
PipedOutputStream 总结
通过源码分析,发现该类没有什么特别的,通过构造或者 connect() 方法接收一个 PipedInputStream对象,然后把要输出信息,交给 PipedInputStream.receive() 方法去接收。
PipedInputStream 源码分析
打开该类后发现比 PipedInputStream 类复杂了好多。
类结构

PipedInputStream 中定义了很多成员变量
1、closedByWriter 是否关闭 PipedOutputStream 流。
2、closedByReader 是否关闭 PipedInputStream 流。
3、connected 输入输出管道流是否成功连接了。
4、readSide、writeSide 读线程和写线程
5、DEFAULT_PIPE_SIZE 默认读写的缓冲区大小为 1024.
6、PIPE_SIZE 对外暴露管道流的读写缓冲区大小(当前包可见)
7、buffer 缓冲区大小
8、in 写入缓冲区下标
9、out 写出缓冲区下标
PipedInputStream 构造及初始化
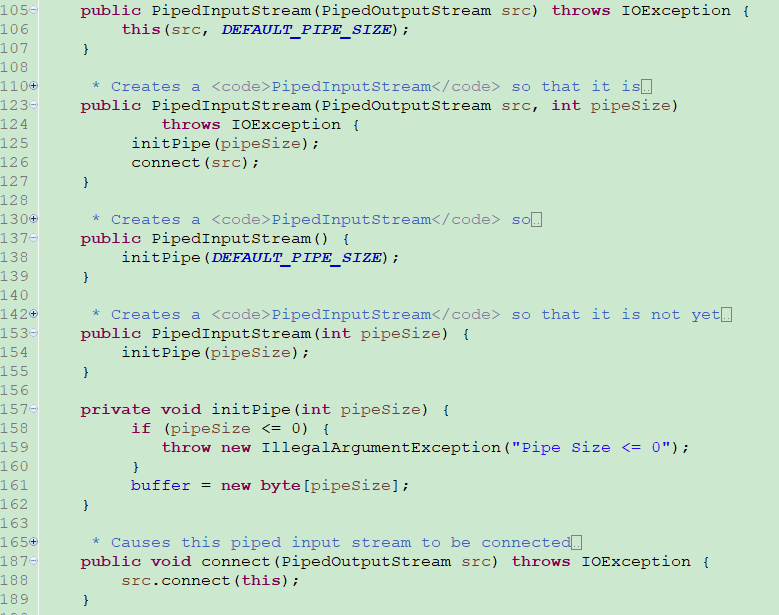
- PipedInputStream 支持有4种构造方法。
1、public PipedInputStream(PipedOutputStream src)
传入一个 PipedOutputStream 参数,并调用 initPipe() 方法创建默认大小(1024)的 buffer。
2、public PipedInputStream(PipedOutputStream src, int pipeSize)
传入一个 PipedOutputStream 参数和 pipeSize参数,调用 initPipe() 方法创建指定大小的 buffer
3、public PipedInputStream()
调用 initPipe() 方法,创建一个默认大小的buffer
4、public PipedInputStream(int pipeSize)
调用 initPipe() 方法,创建一个指定大小的buffer - initPipe 方法
private void initPipe(int pipeSize)
根据 pipeSize 创建 buffer 。 - connect 方法
public void connect(PipedOutputStream src)
connect方法其实还是调用的 PipedOutputStream 类种的 connect 方法。
所以下面这样写法,是等价的,都是调用 PipedOutputStream 类种的 connect 方法。

receive 方法

通过分析 PipedOutputStream 的源码,我们知道,该方法是在 PipedOutputStream.write() 方法种调用的。
- 1、checkStateForReceive()检查是否可以接受数据。(是否可向 buffer 种写入数据);
- 2、获取写线程。PipedOutputStream.write() 中调用的,所以获取的是PipedOutStream 所在的线程;
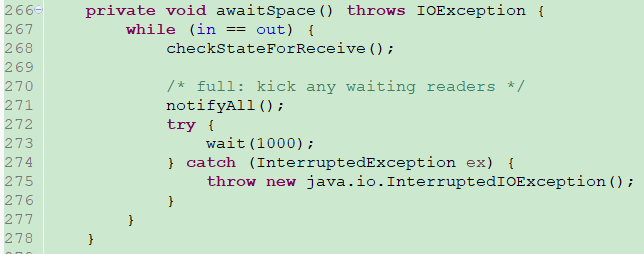
- 3、判断 in==out。如果相等说明,已经缓冲区已经被填充满数据了。这时调用 awaitSpace() 方法,唤醒读线程(读线程可能 wait 状态),让当前线程 wait ,如果没有读线程唤醒写线程,那么写线程会在 awaitSpace() 方法种每隔1秒检查一次是否可写;
为什么 in == out 的时候就是写满缓冲区呢?
比如: buffer 长度为10,现在写了5个字节,又读了5个字节,是不是 in 也等于 out?
其实不会的,为什么?
因为读的时候如果 in==out时,他把 in 的值置为了 -1。详见 read() 方法。
- 4、如果 in<0,就是第一次写或者已经读完 buffer 中已写的数据,这是,把 in 和 out 置为0;
- 5、向buffer 种写入数据。
- 6、如果 in 达到 buffer 的最大长度,则把in 置为 0, 下次开始从0 开始填充。(这里,可以把 buffer 当成一个环形队列)。
awaitSpace() 源码
read() 方法

1、执行各种检查,是否可读。
2、获取读线程并赋值给 readSide 变量。
3、while 循环监听判断是否有写线程写数据,如果没有则等待(每秒检查一次),并唤醒写线程(写线程可能 wait )。
4、读取 buffer 中的数据。 如果读到 buffer 的最后一个元素,则把 out 置为0,下次从下标0开始继续读(循环队列表)。
5、如果 in == out,则把 in 置为 -1 。置为初始状态。相当于清空了缓冲区,从缓冲区的下标 0 开始读写。
available() 方法
获取当前可读的字节数
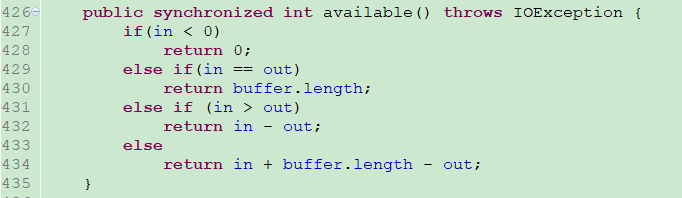
1、如果 in<0; 说明当前没有可读的数据
2、如果 in == out; 说明数据已经填充满了。
3、如果 in > out; 那么in – out 就是 可写的字节数。
4、否则,就是 in < out 的情况。因为它是环形写入的,可能出现 in < out 的情况,所以需要 in + buffer.length – out,才能获取可读字节长度。
PipedInputStream 总结
PipedInputStream 原理其实也很简单,但代码看起来有点懵,它就是通过 wait() 和 notifyAll() 来控制 buffer 是否可读,或可写的。
管道流,做开发这么多年,现在都没有遇到可用的场景。管道流能用到的场景,在并发包种,很多方式都可以实现或代替。比如 java.util.concurrent.Exchanger 类。
java.util.concurrent.Exchanger 的使用场景比管道流使用场景更广泛些。
文章来源于互联网:Java IO 之 管道流 原理分析
1、本站所有资源均从互联网上收集整理而来,仅供学习交流之用,因此不包含技术服务请大家谅解!
2、本站不提供任何实质性的付费和支付资源,所有需要积分下载的资源均为网站运营赞助费用或者线下劳务费用!
3、本站所有资源仅用于学习及研究使用,您必须在下载后的24小时内删除所下载资源,切勿用于商业用途,否则由此引发的法律纠纷及连带责任本站和发布者概不承担!
4、本站站内提供的所有可下载资源,本站保证未做任何负面改动(不包含修复bug和完善功能等正面优化或二次开发),但本站不保证资源的准确性、安全性和完整性,用户下载后自行斟酌,我们以交流学习为目的,并不是所有的源码都100%无错或无bug!如有链接无法下载、失效或广告,请联系客服处理!
5、本站资源除标明原创外均来自网络整理,版权归原作者或本站特约原创作者所有,如侵犯到您的合法权益,请立即告知本站,本站将及时予与删除并致以最深的歉意!
6、如果您也有好的资源或教程,您可以投稿发布,成功分享后有站币奖励和额外收入!
7、如果您喜欢该资源,请支持官方正版资源,以得到更好的正版服务!
8、请您认真阅读上述内容,注册本站用户或下载本站资源即您同意上述内容!
原文链接:https://www.dandroid.cn/archives/17244,转载请注明出处。

评论0