目前大部分数据库系统及文件系统都采用 B-Tree(B 树)或其变种 B+Tree(B+树)作为索引结构。B+Tree 是数据库系统实现索引的首选数据结构。
在 MySQL 中,索引属于存储引擎级别的概念,不同存储引擎对索引的实现方式是不同的,本文主要讨论 MyISAM 和 InnoDB 两个存储引擎的索引实现方式。
MyISAM 索引实现
MyISAM 引擎使用 B+Tree 作为索引结构,叶节点的 data 域存放的是数据记录
的地址。下图是 MyISAM 索引的原理图:
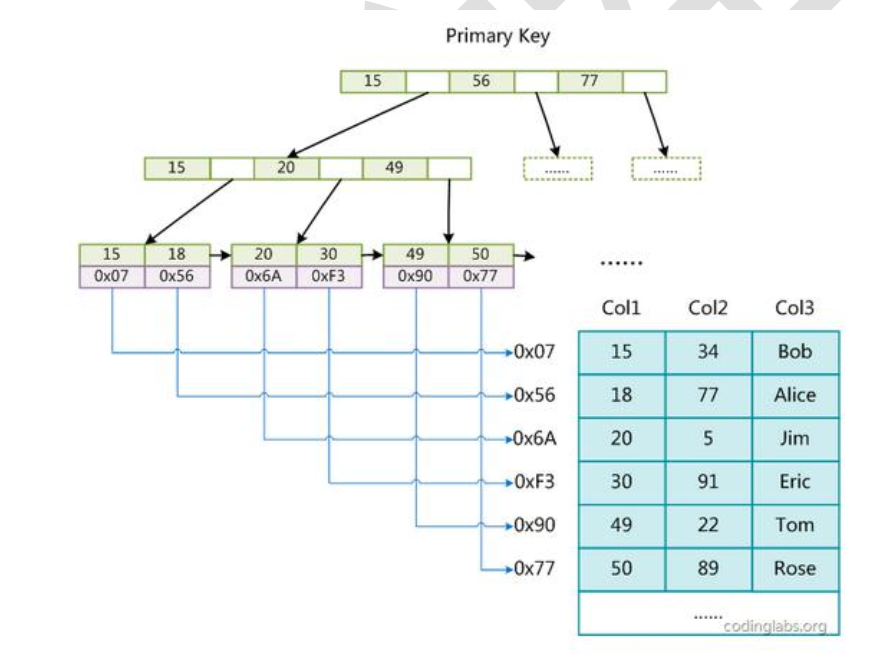
image.png
这里设表一共有三列,假设我们以 Col1 为主键,则图 8 是一个 MyISAM 表的主索引(Primary key)示意。可以看出 MyISAM 的索引文件仅仅保存数据记录的地址。
辅助索引
在 MyISAM 中,主索引和辅助索引(Secondary key)在结构上没有任何区别,只
是主索引要求 key 是唯一的,而辅助索引的 key 可以重复。如果我们在 Col2 上建立一个辅助索引,则此索引的结构如下图所示
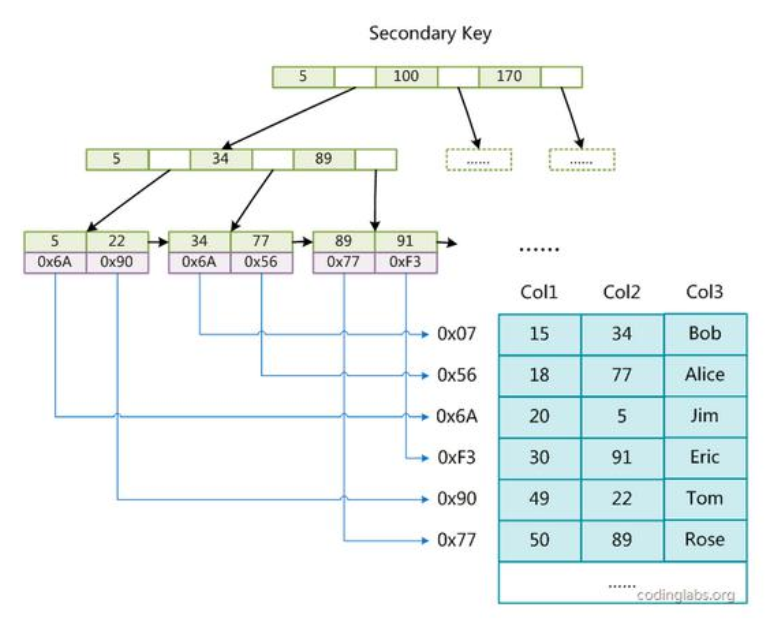
image.png
同样也是一颗 B+Tree,data 域保存数据记录的地址。因此,MyISAM 中索引检索的算法为首先按照 B+Tree 搜索算法搜索索引,如果指定的 Key 存在,则取出其data 域的值,然后以 data 域的值为地址,读取相应数据记录。
MyISAM 的索引方式也叫做“非聚集索引”,之所以这么称呼是为了与 InnoDB的聚集索引区分。
InnoDB 索引实现
虽然 InnoDB 也使用 B+Tree 作为索引结构,但具体实现方式却与 MyISAM 截然不同。
1.第一个重大区别是 InnoDB 的数据文件本身就是索引文件。从上文知道,MyISAM 索引文件和数据文件是分离的,索引文件仅保存数据记录的地址。
而在InnoDB 中,表数据文件本身就是按 B+Tree 组织的一个索引结构,这棵树的叶点data 域保存了完整的数据记录。这个索引的 key 是数据表的主键,因此 InnoDB 表数据文件本身就是主索引。
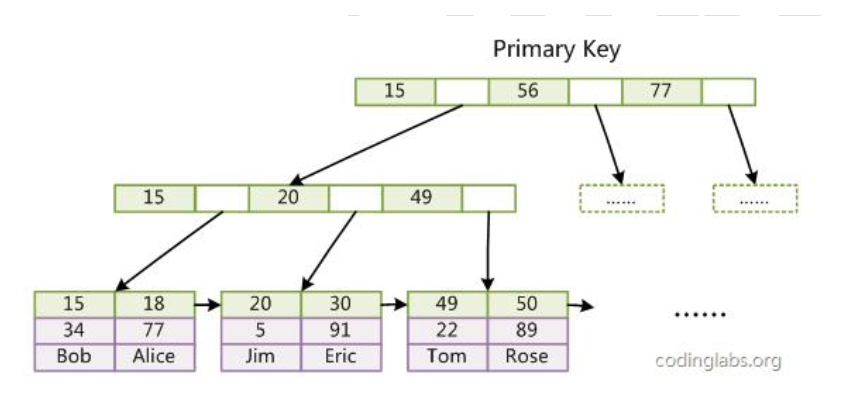
image.png
上图是 InnoDB 主索引(同时也是数据文件)的示意图,可以看到叶节点包含了完整的数据记录。这种索引叫做聚集索引。因为 InnoDB 的数据文件本身要按主键聚集,
1 .InnoDB 要求表必须有主键(MyISAM 可以没有),如果没有显式指定,则 MySQL系统会自动选择一个可以唯一标识数据记录的列作为主键,如果不存在这种列,则MySQL 自动为 InnoDB 表生成一个隐含字段作为主键,类型为长整形。
同时,请尽量在 InnoDB 上采用自增字段做表的主键。因为 InnoDB 数据文件本身是一棵B+Tree,非单调的主键会造成在插入新记录时数据文件为了维持 B+Tree 的特性而频繁的分裂调整,十分低效,而使用自增字段作为主键则是一个很好的选择。如果表使用自增主键,那么每次插入新的记录,记录就会顺序添加到当前索引节点的后续位置,当一页写满,就会自动开辟一个新的页。如下图所示:
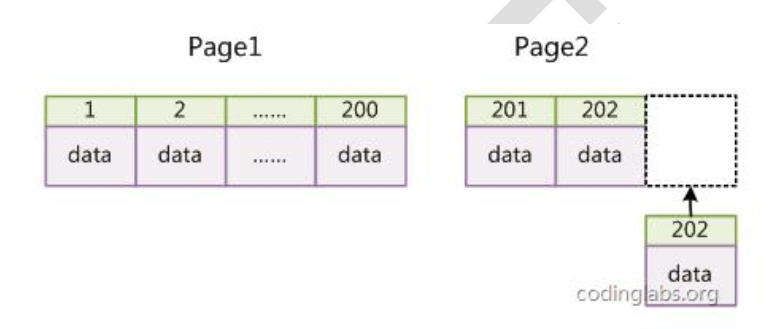
image.png
这样就会形成一个紧凑的索引结构,近似顺序填满。由于每次插入时也不需要移动已有数据,因此效率很高,也不会增加很多开销在维护索引上。
2.第二个与 MyISAM 索引的不同是 InnoDB 的辅助索引 data 域存储相应记录主键的值而不是地址。换句话说,InnoDB 的所有辅助索引都引用主键作为 data 域。
例如,图 11 为定义在 Col3 上的一个辅助索引:
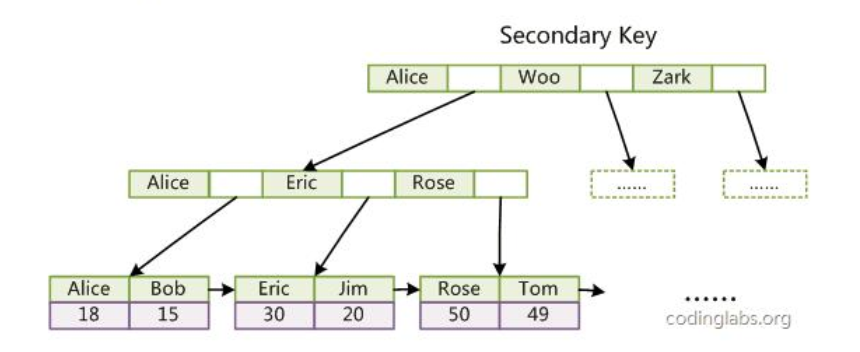
image.png
聚集索引这种实现方式使得按主键的搜索十分高效,但是辅助索引搜索需要检索两遍索引:首先检索辅助索引获得主键,然后用主键到主索引中检索获得记录。
引申:为什么不建议使用过长的字段作为主键?
因为所有辅助索引都引用主索引,过长的主索引会令辅助索引变得过大。
聚簇索引与非聚簇索引
InnoDB 使用的是聚簇索引, 将主键组织到一棵 B+树中, 而行数据就储存在叶子节点上, 若使用”where id = 14″这样的条件查找主键, 则按照 B+树的检索算法即可查找到对应的叶节点, 之后获得行数据。 若对 Name 列进行条件搜索, 则需要两个步骤:
第一步在辅助索引 B+树中检索 Name, 到达其叶子节点获取对应的主键。
第二步使用主键在主索引 B+树种再执行一次 B+树检索操作, 最终到达叶子节点即可获取整行数据。
MyISM 使用的是非聚簇索引, 非聚簇索引的两棵 B+树看上去没什么不同, 节点
的结构完全一致只是存储的内容不同而已, 主键索引 B+树的节点存储了主键, 辅助键索引B+树存储了辅助键。 表数据存储在独立的地方, 这两颗 B+树的叶子节点都使用一个地址指向真正的表数据, 对于表数据来说, 这两个键没有任何差别。 由于索引树是独立的, 通过辅助键检索无需访问主键的索引树。
为了更形象说明这两种索引的区别, 我们假想一个表如下图存储了 4 行数据。 其中Id 作为主索引, Name 作为辅助索引。 图示清晰的显示了聚簇索引和非聚簇索引的差异
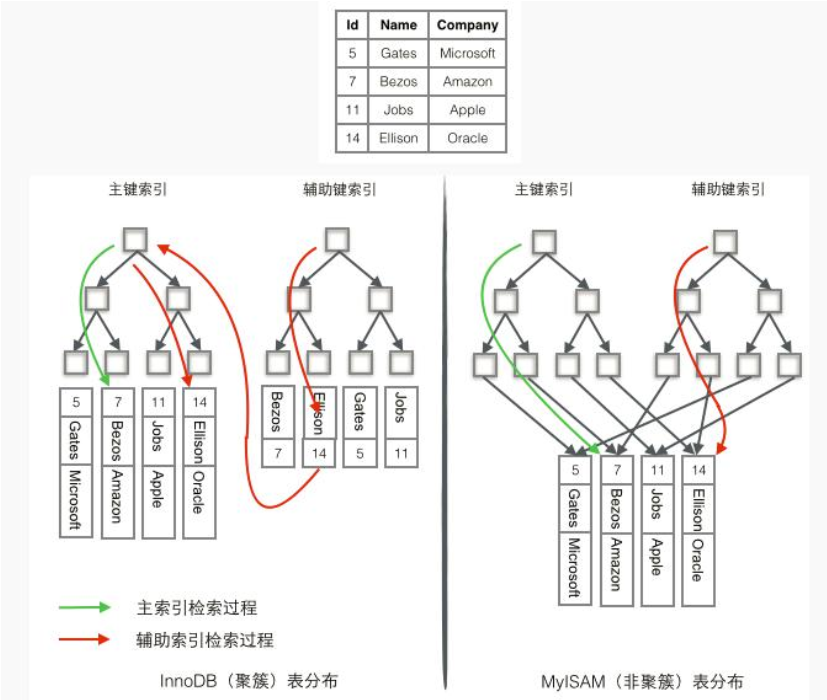
文章来源于互联网:MySQL索引实现原理分析
1、本站所有资源均从互联网上收集整理而来,仅供学习交流之用,因此不包含技术服务请大家谅解!
2、本站不提供任何实质性的付费和支付资源,所有需要积分下载的资源均为网站运营赞助费用或者线下劳务费用!
3、本站所有资源仅用于学习及研究使用,您必须在下载后的24小时内删除所下载资源,切勿用于商业用途,否则由此引发的法律纠纷及连带责任本站和发布者概不承担!
4、本站站内提供的所有可下载资源,本站保证未做任何负面改动(不包含修复bug和完善功能等正面优化或二次开发),但本站不保证资源的准确性、安全性和完整性,用户下载后自行斟酌,我们以交流学习为目的,并不是所有的源码都100%无错或无bug!如有链接无法下载、失效或广告,请联系客服处理!
5、本站资源除标明原创外均来自网络整理,版权归原作者或本站特约原创作者所有,如侵犯到您的合法权益,请立即告知本站,本站将及时予与删除并致以最深的歉意!
6、如果您也有好的资源或教程,您可以投稿发布,成功分享后有站币奖励和额外收入!
7、如果您喜欢该资源,请支持官方正版资源,以得到更好的正版服务!
8、请您认真阅读上述内容,注册本站用户或下载本站资源即您同意上述内容!
原文链接:https://www.dandroid.cn/archives/16936,转载请注明出处。

评论0