引言
在CSDN写了大概140篇文章,一直都是0阅读量,仿佛石沉大海,在掘金能能频频上热搜的文章,在CSDN一点反馈都没有,所以跟文章质量关系不大,主要是曝光量,后面调研一下,发现情况如下
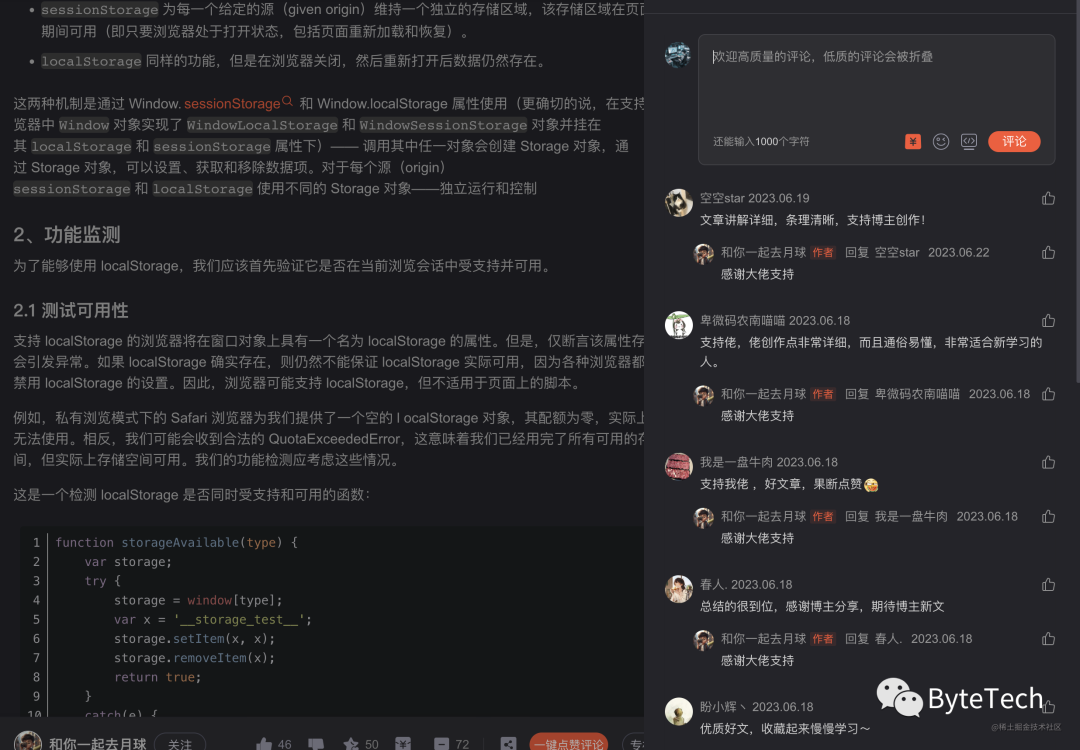
好家伙,基本都是人机评论,后面问了相关博主,原来都是互相刷评论来涨阅读量,enen…,原来CSDN是这样的,真无语,竟然是刷评论,那么就不要怪我用脚本了。
puppeteer入门
❝
先来学习一波puppeteer知识点,其实也不难
❞
puppeteer 简介
Puppeteer 是 Chrome 开发团队在 2017 年发布的一个 Node.js 包, 用来模拟 Chrome 浏览器的运行。
❝
Puppeteer 是一个 Node 库,它提供了一个高级 API 来通过 DevTools 协议控制 Chromium 或 Chrome。Puppeteer 默认以 headless 模式运行,但是可以通过修改配置文件运行“有头”模式。 Chromium 和 Chrome区别
❞
在学puppeteer之前我们先来了解下 headless chrome
什么是 Headless Chrome
-
在无界面的环境中运行 Chrome -
通过命令行或者程序语言操作 Chrome -
无需人的干预,运行更稳定 -
在启动 Chrome 时添加参数 –headless,便可以 headless 模式启动 Chrome
alias chrome="/Applications/Google Chrome.app/Contents/MacOS/Google Chrome" # Mac OS X 命令别名
chrome --headless --disable-gpu --dump-dom https://www.baidu.com # 获取页面 DOM
chrome --headless --disable-gpu --screenshot https://www.baidu.com # 截图
查看更多chrome启动参数 英文中文
puppeteer 能做什么
官方称:“Most things that you can do manually in the browser can be done using Puppeteer”,那么具体可以做些什么呢?
-
网页截图或者生成 PDF -
爬取 SPA 或 SSR 网站 -
UI 自动化测试,模拟表单提交,键盘输入,点击等行为 -
捕获网站的时间线,帮助诊断性能问题 -
……
puppeteer 结构
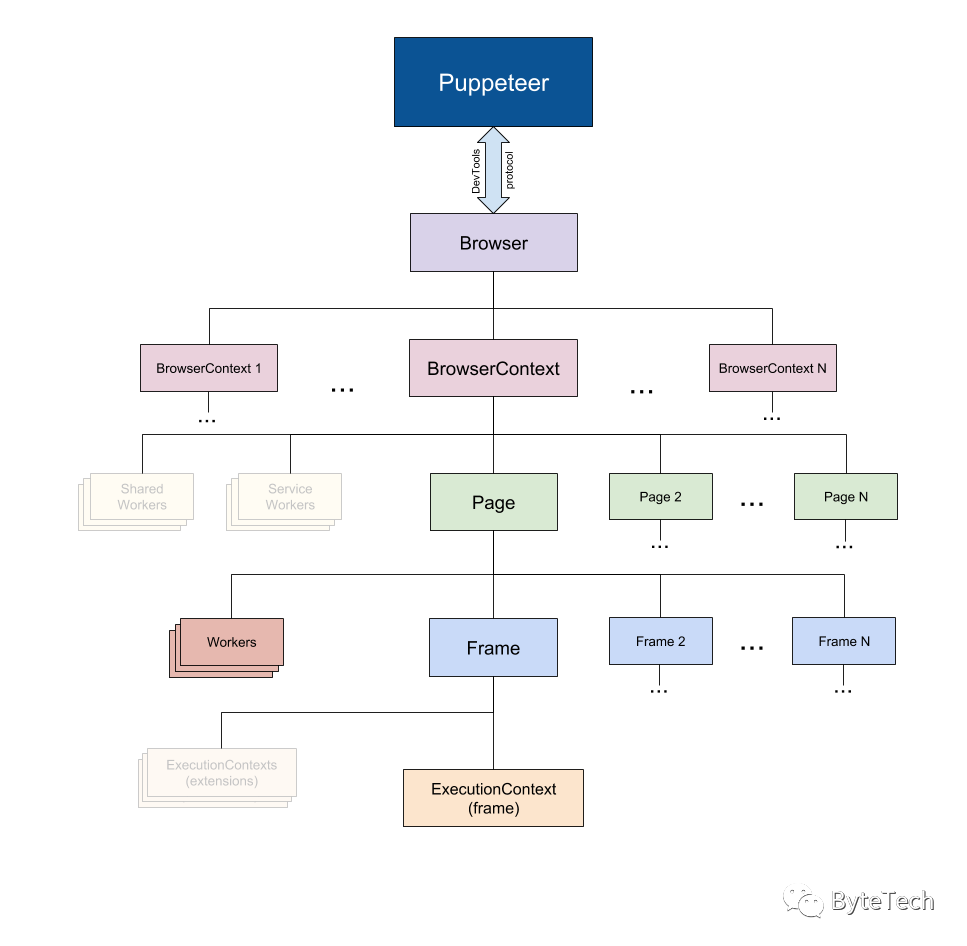
-
Puppeteer 使用 DevTools 协议 与浏览器进行通信。 -
Browser 实例可以拥有浏览器上下文。 -
BrowserContext 实例定义了一个浏览会话并可拥有多个页面。 -
Page 至少有一个框架:主框架。 可能还有其他框架由 iframe 或 框架标签 创建。 -
frame 至少有一个执行上下文 – 默认的执行上下文 – 框架的 JavaScript 被执行。 一个框架可能有额外的与 扩展 关联的执行上下文。
puppeteer 运行环境
查看 Puppeteer 的官方 API 你会发现满屏的 async, await 之类,这些都是 ES7 的规范,所以你需要: Nodejs 的版本不能低于 v7.6.0
npm install puppeteer
# or "yarn add puppeteer"
Note: 当你安装 Puppeteer 时,它会自动下载Chromium,由于Chromium比较大,经常会安装失败~ 可是使用以下解决方案
-
把npm源设置成国内的源 cnpm taobao 等 -
安装时添加–ignore-scripts命令跳过Chromium的下载 npm install puppeteer –ignore-scripts -
安装 puppeteer-core 这个包不会去下载Chromium
puppeteer 基本用法
先打开官方的入门demo
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://example.com');
await page.screenshot({path: 'example.png'});
await browser.close();
})();
上面这段代码就实现了网页截图,先大概解读一下上面几行代码:
-
先通过 puppeteer.launch() 创建一个浏览器实例 Browser 对象 -
然后通过 Browser 对象创建页面 Page 对象 -
然后 page.goto() 跳转到指定的页面 -
调用 page.screenshot() 对页面进行截图 -
关闭浏览器
是不是觉得好简单?
puppeteer.launch(options)
options 参数详解
| 参数名称 | 参数类型 | 参数说明 |
|---|---|---|
| ignoreHTTPSErrors | boolean | 在请求的过程中是否忽略 Https 报错信息,默认为 false |
| headless | boolean | 是否以”无头”的模式运行 chrome, 也就是不显示 UI, 默认为 true |
| executablePath | string | 可执行文件的路劲,Puppeteer 默认是使用它自带的 chrome webdriver, 如果你想指定一个自己的 webdriver 路径,可以通过这个参数设置 |
| slowMo | number | 使 Puppeteer 操作减速,单位是毫秒。如果你想看看 Puppeteer 的整个工作过程,这个参数将非常有用。 |
| args | Array(String) | 传递给 chrome 实例的其他参数,比如你可以使用”–ash-host-window-bounds=1024×768” 来设置浏览器窗口大小。 |
| handleSIGINT | boolean | 是否允许通过进程信号控制 chrome 进程,也就是说是否可以使用 CTRL+C 关闭并退出浏览器. |
| timeout | number | 等待 Chrome 实例启动的最长时间。默认为30000(30秒)。如果传入 0 的话则不限制时间 |
| dumpio | boolean | 是否将浏览器进程stdout和stderr导入到process.stdout和process.stderr中。默认为false。 |
| userDataDir | string | 设置用户数据目录,默认linux 是在 ~/.config 目录,window 默认在 C:Users{USER}AppDataLocalGoogleChromeUser Data, 其中 {USER} 代表当前登录的用户名 |
| env | Object | 指定对Chromium可见的环境变量。默认为process.env。 |
| devtools | boolean | 是否为每个选项卡自动打开DevTools面板, 这个选项只有当 headless 设置为 false 的时候有效 |
puppeteer如何使用
❝
下面介绍 10 个关于使用 Puppeteer 的用例,并在介绍用例的时候会穿插的讲解一些 API,告诉大家如何使用 Puppeteer:
❞
01 获取元素及操作
如何获取元素?
-
page.$(‘#uniqueId’):获取某个选择器对应的第一个元素 -
page.$$(‘div’):获取某个选择器对应的所有元素 -
page.$x(‘//img’):获取某个 xPath 对应的所有元素 -
page.waitForXPath(‘//img’):等待某个 xPath 对应的元素出现 -
page.waitForSelector(‘#uniqueId’):等待某个选择器对应的元素出现
❝
Page.$(selector) 获取单个元素,底层是调用的是 document.querySelector() , 所以选择器的 selector 格式遵循 css 选择器规范
❞
❝
Page.$$(selector) 获取一组元素,底层调用的是 document.querySelectorAll(). 返回 Promise(Array(ElemetHandle)) 元素数组.
❞
const puppeteer = require('puppeteer');
async function run (){
const browser = await puppeteer.launch({headless:false,defaultViewport:{width:1366,height:768}});
const page = await browser.newPage();
await page.goto('https://www.baidu.com');
const input_area = await page.$("#kw");
await input_area.type("Hello Wrold");
const search_btn = await page.$('#su');
await search_btn.click();
}
run();
02 获取元素属性
Puppeteer 获取元素属性跟我们平时写前段的js的逻辑有点不一样,按照通常的逻辑,应该是现获取元素,然后在获取元素的属性。但是上面我们知道 获取元素的 API 最终返回的都是 ElemetHandle 对象,而你去查看 ElemetHandle 的 API 你会发现,它并没有获取元素属性的 API.
事实上 Puppeteer 专门提供了一套获取属性的 API, Page.$eval()
Page.$$eval(selector, pageFunction[, …args]), 获取单个元素的属性,这里的选择器 selector 跟上面 Page.$(selector) 是一样的。
const value = await page.$eval('input[name=search]', input => input.value);
const href = await page.$eval('#a", ele => ele.href);
const content = await page.$eval('.content', ele => ele.outerHTML);
const puppeteer = require('puppeteer');
async function run (){
const browser = await puppeteer.launch({headless:false,defaultViewport:{width:1366,height:768}});
const page = await browser.newPage();
await page.goto('https://www.baidu.com');
const input_area = await page.$("#kw");
await input_area.type("Hello Wrold");
const search_btn = await page.$('#su');
await search_btn.click();
await page.waitFor('div#content_left > div.result-op.c-container.xpath-log',{visible:true});
let resultText = await page.$eval('div#content_left > div.result-op.c-container.xpath-log',ele=> ele.innerText)
console.log("result Text= ",resultText);
}
run();
03 处理多个元素
const puppeteer = require('puppeteer');
async function run() {
const browser = await puppeteer.launch({
headless: false,
defaultViewport: {
width: 1280,
height: 800,
},
slowMo: 200,
});
const page = await browser.newPage();
await page.goto('https://www.baidu.com');
const input_area = await page.$('#kw');
await input_area.type('Hello Wrold');
await page.keyboard.press('Enter');
const listSelector = 'div#content_left > div.result-op.c-container.xpath-log';
// await page.waitForSelector(listSelector);
await page.waitFor(3 * 1000);
const list = await page.$eval(listSelector, (eles) =>
eles.map((ele) => ele.innerText)
);
console.log('List ==', list);
}
run();
04 切换frame
一个 Frame 包含了一个执行上下文(Execution Context),我们不能跨 Frame 执行函数,一个页面中可以有多个 Frame,主要是通过 iframe 标签嵌入的生成的。其中在页面上的大部分函数其实是 page.mainFrame().xx 的一个简写,Frame 是树状结构,我们可以通过page.frames()获取到页面所有的 Frame,如果想在其它 Frame 中执行函数必须获取到对应的 Frame 才能进行相应的处理
const puppeteer = require('puppeteer')
async function anjuke(){
const browser = await puppeteer.launch({headless:false});
const page = await browser.newPage();
await page.goto('https://login.anjuke.com/login/form');
// 切换iframe
await page.frames().map(frame => {console.log(frame.url())})
const targetFrameUrl = 'https://login.anjuke.com/login/iframeform'
const frame = await page.frames().find(frame => frame.url().includes(targetFrameUrl));
const phone= await frame.waitForSelector('#phoneIpt')
await phone.type("13122022388")
}
anjuke();
05 拖拽验证码操作
const puppeteer = require('puppeteer')
async function aliyun(){
const browser = await puppeteer.launch({headless:false,ignoreDefaultArgs:['--enable-automation']});
const page = await browser.newPage();
await page.goto('https://account.aliyun.com/register/register.htm',{waitUntil:"networkidle2"});
const frame = await page.frames().find(frame=>{
console.log(frame.url())
return frame.url().includes('https://passport.aliyun.com/member/reg/fast/fast_reg.htm')
})
const span = await frame.waitForSelector('#nc_1_n1z');
const spaninfo = await span.boundingBox();
console.log('spaninfo',spaninfo)
await page.mouse.move(spaninfo.x,spaninfo.y);
await page.mouse.down();
const div = await frame.waitForSelector('div#nc_1__scale_text > span.nc-lang-cnt');
const divinfo = await div.boundingBox();
console.log('divinfo',divinfo)
for(var i=0;i
await page.mouse.move(spaninfo.x+i,spaninfo.y);
}
await page.mouse.up();
}
aliyun();
06 模拟不同设备
const puppeteer = require('puppeteer');
const devices = require('puppeteer/DeviceDescriptors');
const iPhone = devices['iPhone 6'];
puppeteer.launch().then(async browser => {
const page = await browser.newPage();
await page.emulate(iPhone);
await page.goto('https://www.baidu.com');
// 其他操作...
await browser.close();
});
07 请求拦截
const puppeteer = require('puppeteer');
async function run () {
const browser = await puppeteer.launch({
headless:false,
defaultViewport:{
width:1280,
height:800
}
})
const page = await browser.newPage();
await page.setRequestInterception(true);
page.on('request', interceptedRequest => {
const blockTypes = new Set(['image', 'media', 'font']);
const type = interceptedRequest.resourceType();
const shouldBlock = blockTypes.has(type);
if (shouldBlock) {
interceptedRequest.abort();
} else {
interceptedRequest.continue();
}
});
await page.goto('https://t.zhongan.com/group');
}
run();
08 性能分析
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.tracing.start({path: 'trace.json'});
await page.goto('https://t.zhongan.com/group');
await page.tracing.stop();
browser.close();
})();
09 生成pdf
const URL = 'http://es6.ruanyifeng.com';
const puppeteer = require('puppeteer');
const fs = require('fs');
fs.mkdirSync('es6-pdf');
(async () => {
let browser = await puppeteer.launch();
let page = await browser.newPage();
await page.goto(URL);
await page.waitFor(5000); // 等待五秒,确保页面加载完毕
// 获取左侧导航的所有链接地址及名字
let aTags = await page.evaluate(() => {
let eleArr = [...document.querySelectorAll('#sidebar ol li a')];
return eleArr.map((a) =>{
return {
href: a.href.trim(),
name: a.text
}
});
});
// 先将本页保存成pdf,并关闭本页
console.log('正在保存:0.' + aTags[0].name);
await page.pdf({path: `./es6-pdf/0.${aTags[0].name}.pdf`});
// 遍历节点数组,逐个打开并保存 (此处不再打印第一页)
for (let i = 1, len = aTags.length; i < len; i++) {
let a = aTags[i];
console.log('正在保存:' + i + '.' + a.name);
page = await browser.newPage();
await page.goto(a.href);
await page.waitFor(5000);
await page.pdf({path: `./es6-pdf/${i + '.' + a.name}.pdf`});
}
browser.close();
})
10 自动化发布微博
const puppeteer = require('puppeteer');
const {username,password} = require('./config')
async function run(){
const browser = await puppeteer.launch({
headless:false,
defaultViewport:{width:1200,height:700},
ignoreDefaultArgs:['--enable-automation'],
slowMo:200,
args:['--window-size=1200,700']})
const page = await browser.newPage();
await page.goto('http://wufazhuce.com/',{waitUntil:'networkidle2'});
const OneText = await page.$eval('div.fp-one-cita > a',ele=>ele.innerText);
console.log('OneText:',OneText);
await page.goto('https://weibo.com/',{waitUntil:'networkidle2'});
await page.waitFor(2*1000);
await page.reload();
const loginUserInput = await page.waitForSelector('input#loginname');
await loginUserInput.click();
await loginUserInput.type(username);
const loginUserPasswdInput = await page.waitForSelector('input[type="password"]');
await loginUserPasswdInput.click();
await loginUserPasswdInput.type(password);
const loginBtn = await page.waitForSelector('a[action-type="btn_submit"]')
await loginBtn.click();
const textarea = await page.waitForSelector('textarea[class="W_input"]')
await textarea.click();
await textarea.type(OneText);
const sendBtn = await page.waitForSelector('a[node-type="submit"]');
await sendBtn.click();
}
run();
CSDN的脚本
❝
这里注意CSDN有反扒机制,规则自己琢磨就行,我贴了伪代码,核心代码就不开放,毕竟自己玩玩就行了
❞
const puppeteer = require('puppeteer');
async function autoCommentCSDN(username, password, targetBlogger, commentContent) {
const browser = await puppeteer.launch({ headless: false }); // 打开有头浏览器
const page = await browser.newPage();
// 登录CSDN
await page.goto('https://passport.csdn.net/login');
await page.waitForTimeout(1000); // 等待页面加载
// 切换到最后一个Tab (账号登录)
// 点击“密码登录”
const passwordLoginButton = await page.waitForXPath('//span[contains(text(), "密码登录")]');
await passwordLoginButton.click();
// 输入用户名和密码并登录
const inputFields = await page.$('.base-input-text');
await inputFields[0].type( username);
await inputFields[1].type( password);
await page.click('.base-button');
await page.waitForNavigation();
// // 跳转到博主的首页
await page.goto(`https://blog.csdn.net/${targetBlogger}?type=blog`);
// // 点击第一篇文章的标题,进入文章页面
await page.waitForSelector('.list-box-cont', { visible: true });
await page.click('.list-box-cont');
// // 获取文章ID
console.log('page.url()',page.url())
// await page.waitForTimeout(1000); // 等待页面加载
await page.goto('https://blog.csdn.net/weixin_52898349/article/details/132115618')
await page.waitForTimeout(1000); // 等待页面加载
console.log('开始点击评论按钮...')
console.log('page.url()',page.url())
// 获取当前页面的DOM内容
const bodyHTML = await page.evaluate(() => {
return document.body.innerHTML;
});
console.log(bodyHTML);
// await page.waitForSelector('.comment-side-tit');
// const commentInput = await page.$('.comment-side-tit');
// await commentInput.click();
// 等待评论按钮出现
// 点击评论按钮
// await page.waitForSelector('.comment-content');
// const commentInput = await page.$('.comment-content textarea');
// await commentInput.type(commentContent);
// const submitButton = await page.$('.btn-comment-input');
// await submitButton.click();
// console.log('评论成功!');
// await browser.close();
}
// 请替换以下参数为您的CSDN账号信息、目标博主和评论内容
const username = 'weixin_52898349';
const password = 'xxx!';
const targetBlogger = 'weixin_52898349'; // 目标博主的CSDN用户名
const commentContent = '各位大佬们帮忙三连一下,非常感谢!!!!!!!!!!!'; // 评论内容
autoCommentCSDN(username, password, targetBlogger, commentContent);
1、本站所有资源均从互联网上收集整理而来,仅供学习交流之用,因此不包含技术服务请大家谅解!
2、本站不提供任何实质性的付费和支付资源,所有需要积分下载的资源均为网站运营赞助费用或者线下劳务费用!
3、本站所有资源仅用于学习及研究使用,您必须在下载后的24小时内删除所下载资源,切勿用于商业用途,否则由此引发的法律纠纷及连带责任本站和发布者概不承担!
4、本站站内提供的所有可下载资源,本站保证未做任何负面改动(不包含修复bug和完善功能等正面优化或二次开发),但本站不保证资源的准确性、安全性和完整性,用户下载后自行斟酌,我们以交流学习为目的,并不是所有的源码都100%无错或无bug!如有链接无法下载、失效或广告,请联系客服处理!
5、本站资源除标明原创外均来自网络整理,版权归原作者或本站特约原创作者所有,如侵犯到您的合法权益,请立即告知本站,本站将及时予与删除并致以最深的歉意!
6、如果您也有好的资源或教程,您可以投稿发布,成功分享后有站币奖励和额外收入!
7、如果您喜欢该资源,请支持官方正版资源,以得到更好的正版服务!
8、请您认真阅读上述内容,注册本站用户或下载本站资源即您同意上述内容!
原文链接:https://www.dandroid.cn/archives/16791,转载请注明出处。

评论0