前言
内存问题是软件领域的经典问题,平时藏得很深,在出现问题之前没太多征兆。而一旦爆发问题,问题来源的多样、不易重现、现场信息少、难以定位等困难,就会让人头疼不已。
微信在过去 N 多的版本迭代中,经历了各式各样的内存问题,这些问题包括但不限于 Activity 的泄漏、Cursor 未关闭、线程的过度使用、无节制的创建缓存、以及某个 so 库悄无声息一点点的泄漏内存,等等。有些问题甚至曾倒逼着我们改变了微信的架构(2.x 时代 webview 内核泄露催生了微信多进程架构的改变)。时至今日微信依然偶尔会受到内存问题的挑战,在持续不断的版本迭代中,总会有新的问题被引入并潜藏着。
在解决各种问题的过程中,我们积累了一些相对有效和多面的优化手段及工具,从监控上报到开发阶段的测试检查,为预防和解决问题提供帮助,并还在不断的持续改进。本文打算介绍一下这些工程上的优化实践经验,希望对大家有一些参考价值。
Activity 泄露检测
Activity 泄漏,即因为各种原因导致 Activity 被生命周期远比该 Activity 长的对象直接或间接以强引用持有,导致在此期间 Activity 无法被 GC 机制回收的问题。与其他对象泄漏相比,Android 上的 Activity 一方面提供了与系统交互的 Context,另一方面也是用户与 App 交互的承载者,因此非常容易意外被系统或其他业务逻辑作为一个普通的工具对象长期持有,而且一旦发生泄漏,被牵连导致同样被泄漏的对象也会非常多。此外,由于这类问题在大量爆发之前除了 App 内存占用变大之外并没有 crash 之类的明显征兆,因此在测试阶段主动检测、排查 Activity 泄漏,避免线上出现 OOM 或其他问题就显得非常必要了。
早期我们曾通过自动化测试阶段在内存占用达到阈值后自动触发 Hprof Dump,将得到的 Hprof 存档后由人工通过 MAT 进行分析。在新代码提交速度还不太快的时候,这样做确实也能凑合着解决问题,但随着微信新业务代码越来越多,人工排查后反馈给各 Activity 的负责人,各负责人修复之后再人工确认一遍是否已经修复,这个过程需要反复的情况也越来越多,人工解决的方案已力不从心。
后来我们尝试了 LeakCanary。这款工具除了能给出可读性非常好的检测结果外,对于排查出的问题,还会展示开源社区维护的解决方案,在 Activity 泄漏检测、分析上完全可以代替人力。唯一美中不足的是 LeakCanary 把检测和分析报告都放到了一起,流程上更符合开发和测试是同一人的情况,对批量自动化测试和事后分析就不太友好了。
为此我们在 LeakCanary 的基础上研发了一套 Activity 泄漏的检测分析方案 —— ResourceCanary,作为我们内部质量监控平台 Matrix 的一部分参与到每天的自动化测试流程中。与 LeakCanary 相比 ResourceCanary 做了以下改进:
- 分离检测和分析两部分逻辑。
事实上这两部分本来就可以独立运作,检测部分负责检测和产生 Hprof 及一些必要的附加信息,分析部分处理这些产物即可得到引发泄漏的强引用链。这样一来检测部分就不再和分析、故障解决相耦合,自动化测试由测试平台进行,分析则由监控平台的服务端离线完成,再通知相关开发同学解决问题。三者互不打断对方进程,保证了自动化流程的连贯性。
- 裁剪 Hprof 文件,降低后台存档 Hprof 的开销。
就 Activity 泄漏分析而言,我们只需要 Hprof 中类和对象的描述和这些描述所需的字符串信息,其他数据都可以在客户端就地裁剪。由于 Hprof 中这些数据比重很低,这样处理之后能把 Hprof 的大小降至原来的 1/10 左右,极大降低了传输和存储开销。
实际运行中通过 ResourceCanary,我们排查了一些非常典型的泄漏场景,部分列举如下:
- 匿名内部类隐式持有外部类的引用导致的泄漏
public class ChattingUI extends MMActivity {
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_chatting_ui);
EventCenter.addEventListener(new IListener() {
// 这个 IListener 内部类里有个隐藏成员 this$ 持有了外部的 ChattingUI
@Override
public void onEvent() {
// ...
}
});
}
}
public class EventCenter {
// 此 ArrayList 实例的生命周期为 App 的生命周期
private static List sListeners = new ArrayList();
public void addEventListener(IListener cb) {
// ArrayList 对象持有 cb,cb.this$ 持有 ChattingUI,导致 ChattingUI 泄漏
sListeners.add(cb);
}
}- 各种原因导致的反注册函数未按预期被调用导致的Activity泄漏
- 系统组件导致的 Activity 泄漏,如 LeakCanary 中提到的 SensorManager 和 InputMethodManager 导致的泄漏。
还有特别耗时的 Runnable 持有 Activity,或者此 Runnable 本身并不耗时,但在它前面有个耗时的 Runnable 堵塞了执行线程导致此 Runnable 一直没机会从等待队列里移除,也会引发 Activity 泄漏等等。从来源上这类例子是举不完的,总之任何能构造长期持有 Activity 的强引用的场景都能泄漏掉 Activity,从而泄漏 Activity 持有的大量 View 和其他对象。
事实上,ResourceCanary 将检测与分析分离和大幅裁剪了 Hprof 文件体积的改进是相当重要的,这使我们将 Activity 检查做成自动化变得更容易。我们将 ResourceCanary 的 sdk 植入在微信中,通过每日常规的自动化测试,将发现的问题上报到微信的 Matrix 平台,自动进行统计、栈提取、归责、建单,然后系统会自动通知相关开发同学进行修复,并可以持续跟进修复情况。对有效解决问题的意义非常大。

除了开发同学每天根据 Matrix 平台的报告进行确认修复外,对于这些泄漏,微信客户端还会采取一些主动措施规避掉无法立即解决的泄漏,大致包括:
- 主动切断 Activity 对 View 的引用、回收 View 中的 Drawable,降低 Activity 泄漏带来的影响
- 尽量用 Application Context 获取某些系统服务实例,规避系统带来的内存泄漏
- 对于已知的无法通过上面两步解决的来自系统的内存泄漏,参考 LeakCanary 给出的建议进行规避
Bitmap 分配及回收追踪
Bitmap 一直以来都是 Android App 的内存消耗大户,很多 Java 甚至 native 内存问题的背后都是不当持有了大量大小很大的 Bitmap。
与此同时,Bitmap 有几个特点方便我们对它们进行监控:
- 创建场景较为单一。 Bitmap 通常通过在 Java 层调用 Bitmap.create 直接创建,或者通过 BitmapFactory 从文件或网络流解码。正好,我们有一层对 Bitmap 创建接口调用的封装,基本囊括微信内创建 Bitmap 的全部场景(包括调用外部库产生 Bitmap 也封装在这层接口内)。这层统一接口有利于我们在创建 Bitmap 时进行统一监控,而不需要进行插桩或 hook 等较为 hack 的方法。
- 创建频率较低。 Bitmap 创建的行为不如 malloc 等通用内存分配频繁,本身往往也伴随着耗时较长的解码或处理,因此在创建 Bitmap 时加入监控逻辑,其性能要求不会特别高。即使是获取完整的 Java 堆栈甚至做一些筛选,其耗时相比起解码或者其他图像处理也是微不足道,我们可以执行稍微复杂的逻辑。
- Java 对象的生命周期。 Bitmap 对象的生命周期和普通 Java 对象一样服从 JVM 的 GC,因此我们可以通过 WeakReference 等手段来跟踪 Bitmap 的销毁,而不用像创建一样对销毁也一并跟踪。
针对上述特点,我们加入了一个针对 Bitmap 的高性价比监控:在接口层中将所有被创建出来的 Bitmap 加入一个 WeakHashMap,同时记录创建 Bitmap 的时间、堆栈等信息,然后在适当的时候查看这个 WeakHashMap 看看哪些 Bitmap 仍然存活来判断是否出现 Bitmap 滥用或泄漏。
这个监控对性能消耗非常低,可以在发布版进行。判断是否泄漏则需要耗费一点性能,且目前还需要人工处理。收集泄漏的时机包括:
- 如果是测试环境,比如 Monkey Test 过程中,则使用 “激进模式”,即每次进行 Bitmap 创建的数秒后都检查一次 Java 堆的情况,Java 内存占用超过某个阈值即触发收集逻辑,将所有存活的 Bitmap 信息输出到文件,另外还输出 hprof 辅助查找别的内存泄漏。
- 发布版则采用 “保守模式”,只有在出现 OOM 了之后,才将内存占用 1 MB 以上的 Bitmap 信息输出到 xlog,避免 xlog 过大。
激进模式中阈值目前定为 200 MB,这是因为我们支持的 Android 设备中,最容易出现 OOM 的一批手机的 large heap 限制为 256 MB,一旦 Heap 峰值达到 200 MB 以上且回收不及时,在一些需要类似解码大图的场景下就会出现无法临时分配数十 MB 的内存供图片显示而导致 OOM,因此在 Monkey Test 时认为 Java Heap 占用超过 200 MB 即为异常。
Bitmap 追踪尝试投入到 Monkey Test 后,发现问题最多最突出的,是缓存的滥用问题,最为典型的是使用 static LRUCache 来缓存大尺寸 Bitmap。
private static LruCache sBitmapCache = new LruCache<>(20);
public static Bitmap getBitmap(String path) {
Bitmap bitmap = sBitmapCache.get(path);
if (bitmap != null) {
return bitmap;
}
bitmap = decodeBitmapFromFile(path);
sBitmapCache.put(path, bitmap);
return bitmap;
}比如上面的代码,作用是缓存一些重复使用的 Bitmap 避免重复解码损失性能,但由于 sBitmapCache 是静态的且没有清理逻辑,缓存在其中的图片将永远无法释放,除非 20 个的配额用尽或图片被替换。LruCache 对缓存对象的 个数 进行了限制,但没有对对象的 总大小 进行限制(Java的对象模型也不支持直接获取对象占用内存大小),因此如果缓存里面存放了数个大图或者长图,将长期占用大量内存。此外,不同业务之间不太可能提前考虑缓存可能造成的相互挤压,进一步加剧问题。也正因如此我们还开始推动了内部使用统一的缓存管理组件,从整体上,控制使用缓存的策略和数量。
Native 内存泄漏检测
Native 层内存泄漏通常是指各种原因导致的已分配内存未得到有效释放,导致可用内存越来越少直到 crash 的问题。由于Native 层没有 GC 机制,内存管理行为非常可控,检测起来确实也简单许多——直接拦截内存分配和释放相关的函数看一下是否配对即可。
我们首先在单个 so 上尝试了一些成熟的方案:
- valgrind
App 明显变得卡顿,检测结果没有太大帮助,而且 valgrind 在 Android 上的部署太麻烦了,要在几百台测试机器上部署是个很大的问题。
- asan
跟文档描述得差不多,检测阶段开销确实比 valgrind 少,但是 App 还是变卡了,自动化测试时容易 ANR。回溯堆栈阶段容易 crash。另外我们的一些历史悠久的 so 按 asan 的要求用 clang 编译之后可能存在 bug,这点也成为了采用此方案的阻碍。
对上述结果我们的猜想是这些工具除了本身开销之外,大而全的功能,诸如双重释放,地址合法性检测,越界访问检测也增加了运行时开销。按此思路我们又改用系统自带的 malloc_debug 进行检测,但 malloc_debug 在堆栈回溯阶段会产生一个必现的 crash,按照网上资料和厂商的反馈的说法,应该是它依赖 stl 库里的 __Unwind 系列函数需要的数据结构在不同的 stl 库里定义不同导致的,然而由于一些原因,被检测的 so 里有些已经不具备换 stl 库重编的条件了。这样的状况迫使我们自研一套方案解决问题。
根据之前的尝试,实际上我们需要研发两个方案组合使用。对于不方便重编的库,我们采用一个不需要重编的方案舍弃一些信息以换取对泄漏的定位能力;对于易于重编的库,我们采用一个不需要 clang 环境的方案保证能在不引入 bug 的情况下拿到 asan 能拿到的泄漏内存分配位置的堆栈信息。当然,两个方案都要足够轻,保证不会产生 ANR 中断自动化测试过程。
限于篇幅,这里不再展开介绍方案原理,只大概说明两个方案的思路:
- 无法重编的情况:PLT hook 拦截被测库的内存分配函数,重定向到我们自己的实现后记录分配的内存地址、大小、来源 so 库路径等信息,定期扫描分配与释放是否配对,对于不配对的分配输出我们记录的信息。
- 可重编的情况:通过 gcc 的 -finstrument-functions 参数给所有函数插桩,桩中模拟调用栈入栈出栈操作;通过 ld 的 –wrap 参数拦截内存分配和释放函数,重定向到我们自己的实现后记录分配的内存地址、大小、来源 so 以及插桩记录的调用栈此刻的内容,定期扫描分配与释放是否配对,对于不配对的分配输出我们记录的信息。
实测中这两个方案为每次内存分配带来的额外开销小于 10ns,总体开销的变化几乎可忽略不计。我们通过这两套方案组合除了发现一个棘手的新问题外,还顺便检测了使用多年的基础网络协议 so 库,并成功找出隐藏多年的十多处小内存泄漏点,降低内存地址的碎片化。
线程监控
常见的 OOM 情况大多数是因为内存泄漏或申请大量内存造成的,比较少见的有下面这种跟线程相关情况,但在我们 crash 系统上有时能发现一些这样的问题。
java.lang.OutOfMemoryError: pthread_create (1040KB stack) failed: Out of memory原因分析
OutOfMemoryError 这种异常根本原因在于申请不到足够的内存造成的,直接的原因是在创建线程时初始 stack size 的时候,分配不到内存导致的。这个异常是在 /art/runtime/thread.cc 中线程初始化的时候 throw 出来的。
void Thread::CreateNativeThread(
JNIEnv* env, jobject java_peer, size_t stack_size, bool is_daemon) {
...
int pthread_create_result = pthread_create(
&new_pthread, &attr, Thread::CreateCallback, child_thread);
if (pthread_create_result != 0) {
env->SetLongField(java_peer, WellKnownClasses::java_lang_Thread_nativePeer, 0);
{
std::string msg(StringPrintf("pthread_create (%s stack) failed: %s",
PrettySize(stack_size).c_str(), strerror(pthread_create_result)));
ScopedObjectAccess soa(env);
soa.Self()->ThrowOutOfMemoryError(msg.c_str());
}
}
}调用这个 pthread_create 的方法去 clone 一个线程,如果返回 pthread_create_result 不为 0,则代表初始化失败。什么情况下会初始化失败,pthread_create 的具体逻辑是在 /bionic/libc/bionic/pthread_create.cpp 中完成:
int pthread_create(pthread_t* thread_out, pthread_attr_t const* attr,
void* (*start_routine)(void*), void* arg) {
...
pthread_internal_t* thread = NULL;
void* child_stack = NULL;
int result = __allocate_thread(&thread_attr, &thread, &child_stack);
if (result != 0) {
return result;
}
...
}
static int __allocate_thread(pthread_attr_t* attr, pthread_internal_t** threadp, void** child_stack) {
size_t mmap_size;
uint8_t* stack_top;
...
attr->stack_base = __create_thread_mapped_space(mmap_size, attr->guard_size);
if (attr->stack_base == NULL) {
return EAGAIN; // EAGAIN != 0
}
...
return 0;
}可以看到每个线程初始化都需要 mmap 一定的 stack size,在默认的情况下一般初始化一个线程需要 mmap 1M 左右的内存空间,在 32bit 的应用中有 4g 的 vmsize,实际能使用的有 3g+,按这种估算,一个进程最大能创建的线程数可达 3000+,当然这是理想的情况,在 linux 中对每个进程可创建的线程数也有一定的限制(/proc/pid/limits)而实际测试中,我们也发现不同厂商对这个限制也有所不同,而且当超过系统进程线程数限制时,同样会抛出这个类型的 OOM。
可见对线程数量的限制,可以一定程度避免 OOM 的发生。所以我们也开始对微信的线程数进行了监控统计。
监控上报
我们在灰度版本中通过一个定时器 10 分钟 dump 出应用所有的线程,当线程数超过一定阈值时,将当前的线程上报并预警,通过对这种异常情况的捕捉,我们发现微信在某些特殊场景下,确实存在线程泄漏以及短时间内线程暴增,导致线程数过大(500+)的情况,这种情况下再创建线程往往容易出现 OOM。
在定位并解决这几个问题后,我们的 crash 系统和厂商的反馈中这种类型 OOM 确实降低了不少。所以监控线程数,收敛线程也成为我们降低 OOM 的有效手段之一。
内存监控
Android 系统中,需要关注两类内存的使用情况,物理内存和虚拟内存。通常我们使用 Memory Profiler 的方式查看 APP 的内存使用情况。
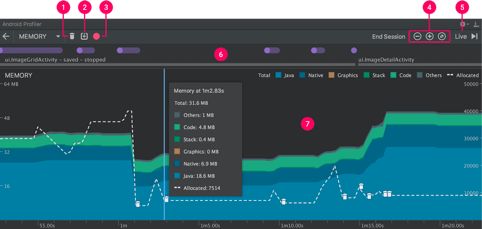
在默认视图中,我们可以查看进程总内存占用、JavaHeap、NativeHeap,以及 Graphics、Stack、Code 等细分类型的内存分配情况。当系统内存不足时,会触发 onLowMemory。在 API Level 14及以上,则有更细分的 onTrimMemory。实际测试中,我们发现 onTrimMemory 的 ComponentCallbacks2.TRIM_MEMORY_COMPLETE 并不等价于 onLowMemory,因此推荐仍然要监听 onLowMemory 回调。
除了旧有的大盘粗粒度内存上报,我们正在建设相对精细的内存使用情况监控并集成到 Matrix 平台上。进行监控方案前,我们需要运行时获得各项内存使用数据的能力。通过 ActivityManager 的 getProcessMemoryInfo,我们获得微信进程的 Debug.MemoryInfo 数据(注意:这个接口在低端机型中可能耗时较久,不能在主线程中调用,且监控调用耗时,在耗时过大的机型上,屏蔽内存监控模块)。通过 hook Debug.MemoryInfo 的 getMemoryStat 方法(需要 23 版本及以上),我们可以获得等价于 Memory Profiler 默认视图中的多项数据,从而获得细分内存使用情况。此外,通过 Runtime 可获得 DalvikHeap;通过 Debug.getNativeHeapAllocatedSize 可获得 NativeHeap。至此,我们可以获得低内存发生时,微信的虚拟内存、物理内存的各项数据,从而实现监控。
内存监控将分为常规监控和低内存监控两个场景。
- 常规内存监控 —— 微信使用过程中,内存监控模块会根据斐波那契数列的特性,每隔一段时间(最长30分钟)获取内存的使用情况,从而获得微信随使用时间而变化的内存曲线。
- 低内存监控 —— 通过 onLowMemory 的回调,或者通过 onTrimMemory 回调且不同的标记位,结合 ActivityManager.MemoryInfo 的 lowMemory 标记,我们可以获得低内存的发生时机。这里需要注意,只有物理内存不足时,才会引起 onLowMemory 回调。超过虚拟内存的大小限制则直接触发 OOM 异常。因此我们也监听虚拟内存的占用情况,当虚拟内存占用超过最大限制的 90% 时,触发为低内存告警。低内存监控将监控低内存的发生频率、发生时各项内存使用情况监控、发生时微信的当前场景等。
兜底保护
除了上面的各种问题及解决手段外,面对各种未知的、难以及时发现问题,目前我们也提出了一个兜底保护策略进行尝试。
从大盘统计的数据上看,我们发现微信主进程存活的时间超过一天的用户达千万级别,占比 1.5%+,倘若应用本身或系统底层存在细微的内存泄漏,短时间上不会造成 OOM,但在长时间的使用中,会使得应用占用内存越积越大,最终也会造成 OOM 情况发生。在这种情况下,我们也在思考,如果可以提前知道内存的占用情况,以及用户当前的使用场景,那么我们可以将这种异常的情况进行兜底保护,来避免不可控的且容易让用户感知到的 OOM 现象。
如何兜底
OOM 会使得进程被杀,实际上也是系统处理异常所抛出来的信号及处理方式。如果应用本身也充当起这个角色,相比系统而言,我们可以根据具体场景,更加灵活的提前处理这种异常情况。其中最大的好处在于,可以在用户无感知的情况下,在接近触发系统异常前,选择合适的场景杀死进程并将其重启,使得应用的内存占用回到正常情况,这不为是一种好的兜底方式。
这里我们主要考虑了几种条件:
- 微信是否在主界面退到后台 且 位于后台的时间超过 30 分钟
- 当前时间为凌晨 2~5 点
- 不存在前台服务(存在通知栏,音乐播放栏等情况)
- java heap 必须大于当前进程最大可分配的 85% || native 内存大于 800M || vmsize 超过了 4G(微信 32bit)的 85%
- 非大量的流量消耗(每分钟不超过 1M) && 进程无大量 CPU 调度情况
在满足以上几种条件下,杀死当前微信主进程并通过 push 进程重新拉起及初始化,来进行兜底保护。在用户角度,当用户将微信切回前台时,不会看到初始化界面,还是位于主界面中,所以也不会感到突兀。从本地测试及灰度的结果上看,应用上该兜底策略,可以有效的减少用户出现 OOM 的情况,在灰度的 5w 用户中,有 3、4 个是命中了这个兜底策略,但具体兜底的策略是否合理,还需要经过更严格的测试才能确认上线。
总结
通过上面的文章,我们尽可能多的介绍了多个方面的内存问题优化手段和工程实践。因为篇幅有限,一些不那么显著的问题和不少细节无法详细展开。总的来说,我们优化实践的思路是在研发阶段不断实现更多的工具和组件,系统性的并逐步提升自动化程度从而提升发现问题的效率。
当然不得不提的是,即使做了这么多努力,内存问题仍没有彻底消灭,仍有问题会因为缺少信息而难以定位原因、或因为测试路径无法覆盖而无法提前发现,还有兼容性的问题、引入的外部组件有泄漏等等,以及我们还需要更多的系统化和自动化,这是我们还在不断优化和改进的方向。
文章来源于互联网:微信 Android 终端内存优化实践
1、本站所有资源均从互联网上收集整理而来,仅供学习交流之用,因此不包含技术服务请大家谅解!
2、本站不提供任何实质性的付费和支付资源,所有需要积分下载的资源均为网站运营赞助费用或者线下劳务费用!
3、本站所有资源仅用于学习及研究使用,您必须在下载后的24小时内删除所下载资源,切勿用于商业用途,否则由此引发的法律纠纷及连带责任本站和发布者概不承担!
4、本站站内提供的所有可下载资源,本站保证未做任何负面改动(不包含修复bug和完善功能等正面优化或二次开发),但本站不保证资源的准确性、安全性和完整性,用户下载后自行斟酌,我们以交流学习为目的,并不是所有的源码都100%无错或无bug!如有链接无法下载、失效或广告,请联系客服处理!
5、本站资源除标明原创外均来自网络整理,版权归原作者或本站特约原创作者所有,如侵犯到您的合法权益,请立即告知本站,本站将及时予与删除并致以最深的歉意!
6、如果您也有好的资源或教程,您可以投稿发布,成功分享后有站币奖励和额外收入!
7、如果您喜欢该资源,请支持官方正版资源,以得到更好的正版服务!
8、请您认真阅读上述内容,注册本站用户或下载本站资源即您同意上述内容!
原文链接:https://www.dandroid.cn/archives/16046,转载请注明出处。

评论0