
阿里妹导读
代码质量
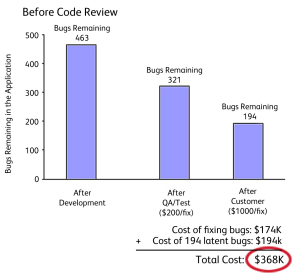
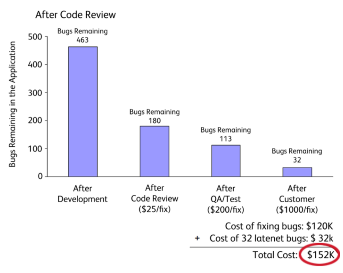
技术交流
卓越工程
挑战1:CR的代码改动范围过大
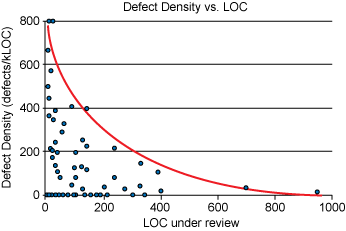
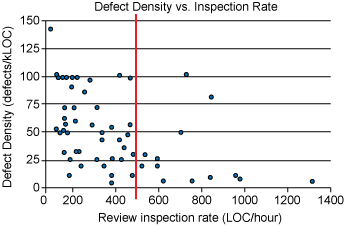
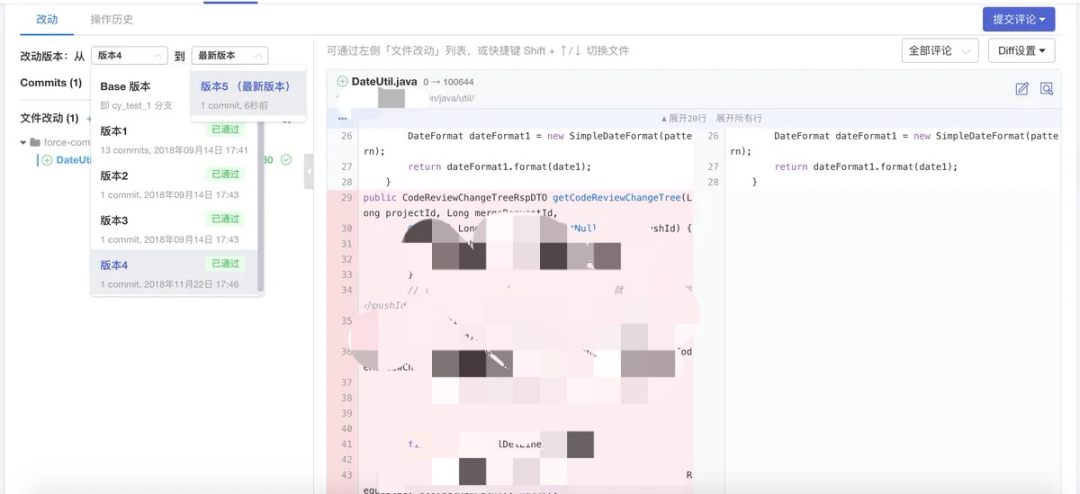
挑战2:CR对评审者全局知识要求很高
- public Level queryLevel(LevelQueryRequest request) {+ public Level queryLevelWithExpireRefresh(LevelQueryRequest request) {Level result = levelRepository.findLevelWithoutInit(request.getId());if (null == result || isExpired(result.getEndTime())) {// 如果等级为空,兜底返回L0;等级已过期,实时返回默认等级,并异步刷新if (result == null) {result = levelRepository.buildInitLevel(request.getId(), LevelEnum.L0);}//查询为空,或者已过期发送消息,刷新等级- LevelRefreshRequest refreshRequest = buildRefreshRequest(request);- levelWriteService.refreshLevel(message.getId(), refreshRequest);+ RefreshMessage refreshMessage = buildRefreshMessage(request);+ refreshMessageProducer.sendMessage(refreshMessage);}return result;}
- public class RefreshMessageListener extends AbstractMessageListener {+ public class RefreshMessageListener extends AbstractOrderlyMessageListener {- private LevelWriteService levelWriteService;+ private LevelWriteRegionalService levelWriteRegionalService;protected boolean process(String tags, String msgId, String receivedMsg) {RefreshMessage message = JSON.parseObject(receivedMsg, RefreshMessage.class);if (message == null || message.getId() == null) {log.warn("message is invalid, ignored, src={}", receivedMsg);return true;}LevelRefreshRequest refreshRequest = buildRefreshRequest(message);- levelWriteService.refreshLevel(message.getId(), refreshRequest);+ levelWriteRegionalService.refreshLevel(message.getId(), refreshRequest);return true;}}
-
为什么存在等级为空的情况?
-
为什么要设计成读时写?
-
为什么不是直接计算等级,而需要用消息队列?
-
为什么要用Regional(区域化)接口和有序消息刷新等级?
挑战3:CR价值最大化需要团队具备卓越工程基因
CASE1:一个业务使用3个时间穿越开关
背景
private static final String CODE = "BENEFIT_TIME_THROUGH";public Date driftedNow(String userId) {try {TimeMockResult result = timeThroughService.getFutureTime(CODE, userId);if (result.isSuccess()) {return new Date(result.getData());}} catch (Throwable t) {log.error("timeThroughService error. userId={}", userId, t);}return new Date();}
观点1:彻底服务化
观点2:富客户端
观点3:配置统一,重复代码三处收拢为两处
总结:
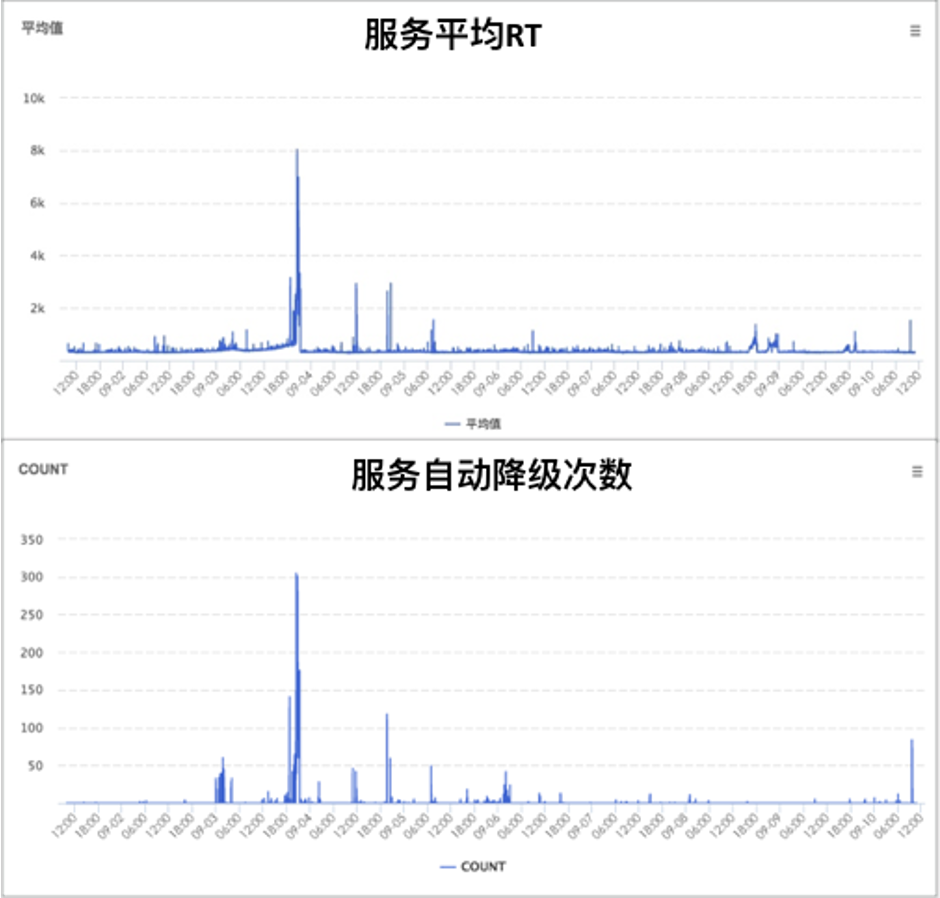
CASE2:SSR(服务端渲染)API稳定性优化
背景

// 提交任务ioTaskList.stream().forEach(t -> futures.add(pool.submit(() -> t.service.invoke())));// 阻塞获取任务结果futures.stream().forEach(f -> {try {result.add(f.get());} catch (Exception e) {log.error(e.getMessage(), e);}});
Step1:增加固定超时控制
// 提交任务ioTaskList.stream().forEach(t -> futures.add(pool.submit(() -> t.service.invoke())));// 阻塞获取任务结果futures.stream().forEach(f -> {try {- result.add(f.get());+ result.add(f.get(1000, TimeUnit.MICROSECONDS));} catch (Exception e) {log.error(e.getMessage(), e);}});
Step2:自适应超时控制
public abstract class BaseService<T> implements Service {public T invoke(ServiceContext context) {Entry entry = null;try {// 根据service类别构造降级资源String resourceName = "RESOURCE_" + name();entry = SphU.entry(resourceName);try {// 未触发降级,正常调用后端服务return realInvoke(context);} catch (Exception e) {// 业务异常,记录错误日志,返回出错信息return failureResult(context);}} catch (BlockException e) {// 被降级,可以fail fast或返回兜底数据return degradeResult(context);} finally {entry.exit();}}public abstract T realInvoke();}
Step3:自适应超时控制+自定义资源key
public abstract class BaseService<T> implements Service {public T invoke(ServiceContext context) {Entry entry = null;try {// 这里的key由service实现,融合了服务类型和自定义key构造降级资源String resourceName = "RESOURCE_" + key(context);entry = SphU.entry(resourceName);try {// 未触发降级,正常调用后端服务return realInvoke(context);} catch (Exception e) {// 业务异常,记录错误日志,返回出错信息return failureResult(context);}} catch (BlockException e) {// 被降级,可以fail fast或返回兜底数据return degradeResult(context);} finally {entry.exit();}}public abstract String key(ServiceContext context);public abstract T realInvoke();}
总结:
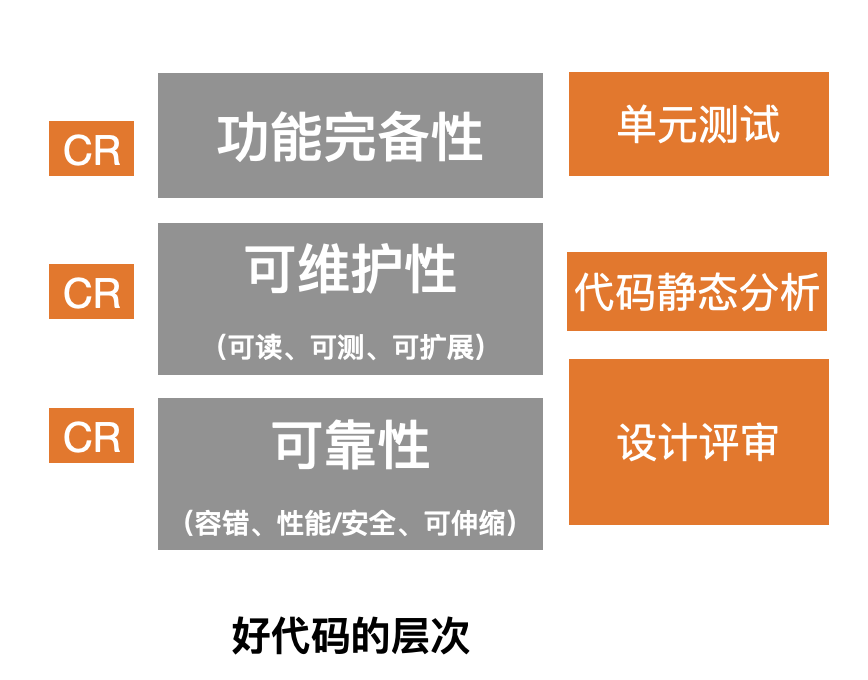
Code Review的边界
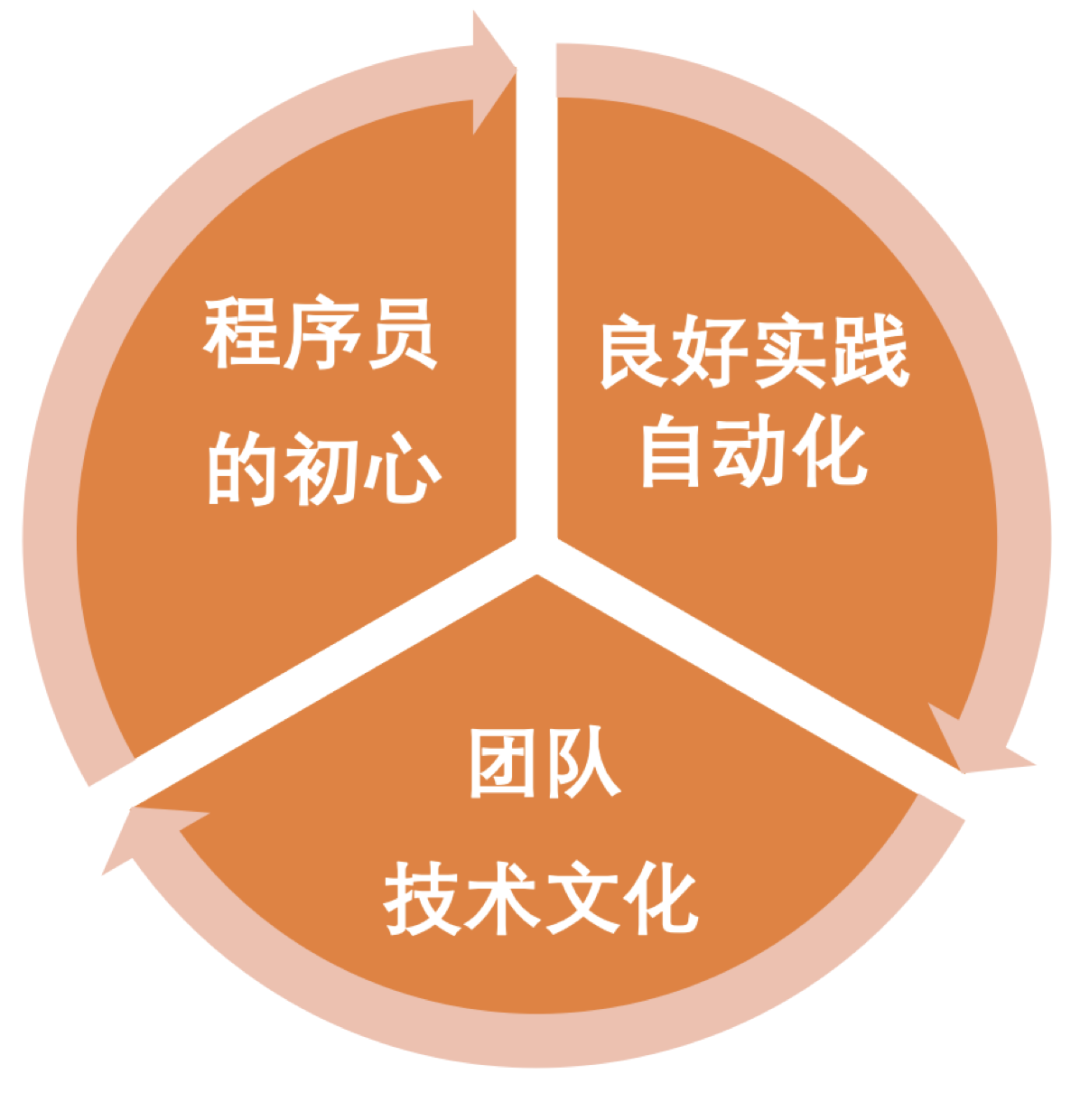
出发点:程序员的初心
看不见的手:自动代码扫描
看得见的手:Team Leader的重视
参考:
-
https://en.wikipedia.org/wiki/Code_review -
https://smartbear.com/learn/code-review/agile-code-review-process/ -
Lessons From Google: How Code Reviews Build Company Culture -
阿里巴巴Java编码规约:https://github.com/alibaba/p3c -
五种Code Review反模式:https://blogs.oracle.com/javamagazine/post/five-code-review-antipatterns -
Capers Jones对软件质量的研究分享:http://sqgne.org/presentations/2012-13/Jones-Sep-2012.pdf -
Modern Code Review: A Case Study at Google:https://sback.it/publications/icse2018seip.pdf -
智能编码插件:https://developer.aliyun.com/tool/cosy
阿里云开发者社区,千万开发者的选择
阿里云开发者社区,百万精品技术内容、千节免费系统课程、丰富的体验场景、活跃的社群活动、行业专家分享交流,欢迎点击【阅读原文】加入我们。
阅读全文
下载说明:
1、本站所有资源均从互联网上收集整理而来,仅供学习交流之用,因此不包含技术服务请大家谅解!
2、本站不提供任何实质性的付费和支付资源,所有需要积分下载的资源均为网站运营赞助费用或者线下劳务费用!
3、本站所有资源仅用于学习及研究使用,您必须在下载后的24小时内删除所下载资源,切勿用于商业用途,否则由此引发的法律纠纷及连带责任本站和发布者概不承担!
4、本站站内提供的所有可下载资源,本站保证未做任何负面改动(不包含修复bug和完善功能等正面优化或二次开发),但本站不保证资源的准确性、安全性和完整性,用户下载后自行斟酌,我们以交流学习为目的,并不是所有的源码都100%无错或无bug!如有链接无法下载、失效或广告,请联系客服处理!
5、本站资源除标明原创外均来自网络整理,版权归原作者或本站特约原创作者所有,如侵犯到您的合法权益,请立即告知本站,本站将及时予与删除并致以最深的歉意!
6、如果您也有好的资源或教程,您可以投稿发布,成功分享后有站币奖励和额外收入!
7、如果您喜欢该资源,请支持官方正版资源,以得到更好的正版服务!
8、请您认真阅读上述内容,注册本站用户或下载本站资源即您同意上述内容!
原文链接:https://www.dandroid.cn/archives/12651,转载请注明出处。
1、本站所有资源均从互联网上收集整理而来,仅供学习交流之用,因此不包含技术服务请大家谅解!
2、本站不提供任何实质性的付费和支付资源,所有需要积分下载的资源均为网站运营赞助费用或者线下劳务费用!
3、本站所有资源仅用于学习及研究使用,您必须在下载后的24小时内删除所下载资源,切勿用于商业用途,否则由此引发的法律纠纷及连带责任本站和发布者概不承担!
4、本站站内提供的所有可下载资源,本站保证未做任何负面改动(不包含修复bug和完善功能等正面优化或二次开发),但本站不保证资源的准确性、安全性和完整性,用户下载后自行斟酌,我们以交流学习为目的,并不是所有的源码都100%无错或无bug!如有链接无法下载、失效或广告,请联系客服处理!
5、本站资源除标明原创外均来自网络整理,版权归原作者或本站特约原创作者所有,如侵犯到您的合法权益,请立即告知本站,本站将及时予与删除并致以最深的歉意!
6、如果您也有好的资源或教程,您可以投稿发布,成功分享后有站币奖励和额外收入!
7、如果您喜欢该资源,请支持官方正版资源,以得到更好的正版服务!
8、请您认真阅读上述内容,注册本站用户或下载本站资源即您同意上述内容!
原文链接:https://www.dandroid.cn/archives/12651,转载请注明出处。

评论0